Тема 1. Введение в тестирование программного обеспечения. Тестирование программного обеспечения — процесс анализа программного средства и сопутствующей документации с целью выявления дефектов и повышения качества продукта
На протяжении десятилетий развития разработки ПО к вопросам тестирования и обеспече- ния качества подходили очень и очень по-разному. Можно выделить несколько основных «эпох тестирования». В 50–60-х годах прошлого века процесс тестирования был предельно формализован, отделён от процесса непосредственной разработки ПО и «математизирован». Фактически тестирование представляло собой скорее отладку программ (debugging). Существовала концепция т.н. «ис- черпывающего тестирования (exhaustive testing)» — проверки всех возможных путей выполне- ния кода со всеми возможными входными данными. Но очень скоро было выяснено, что исчер- пывающее тестирование невозможно, т.к. количество возможных путей и входных данных очень велико, а также при таком подходе сложно найти проблемы в документации.
Задание 1.1.a:
представьте, что ваша программа по трём введённым целым числам определяет, может ли существовать треугольник с такими длинами сторон. Допустим, что ваша программа выполняется в некоей изолированной идеальной среде, и вам все- го-то осталось проверить корректность её работы на трёх 8-байтовых знаковых целых числах. Вы используете автоматизацию, и компьютер может провести 100 миллионов проверок в секунду. Сколько займёт проверка всех вариантов? А задумались ли вы, как подготовить для этого теста проверочные данные (на осно- ве которых можно определить, верно ли сработала программа в каждом конкретном случае)?
-
байт; -
слово; -
двойное слово; -
учетверенное слово.

Байт — восемь последовательно расположенных битов.Биты нумеруются от 0 до 7, при этом бит 0 является самым младшим значащим битом. Обратим внимание, байт – наименьшая адресуемая ячейка памяти.
Целый тип без знака — двоичное значение числа без знака (8, 16 или 32 бита).
Числовые диапазоны:
байт — от 0 до 255;
слово — от 0 до 65 535;
двойное слово — от 0 до 232–1.
Целый тип со знаком — двоичное значение числа со знаком (8, 16 или 32 бита).
Знак содержится в 7, 15 или 31-м бите соответственно.
Отрицательные числа представляются в дополнительном коде.
Числовые диапазоны:
8-разрядное целое — от –128 до +127;
16-разрядное целое — от –32 768 до +32 767;
32-разрядное целое — от –231 до +231–1.
Указатель на память
Указатель на память ближнего типа — 32-разрядный логический адрес, представляющий собой относительное смещение в байтах от начала сегмента.
Указатель на память дальнего типа — 48-разрядный логический адрес, состоящий из двух частей:
В 70-х годах фактически родились две фундаментальные идеи тестирования: тестирование сначала рассматривалось как процесс доказательства работоспособности программы в некото- рых заданных условиях (positive testing5), а затем — строго наоборот: как процесс доказательства неработоспособности программы в некоторых заданных условиях (negative testing). Это вну- треннее противоречие не только не исчезло со временем, но и в наши дни многими авторами совершенно справедливо отмечается как две взаимодополняющие цели тестирования. Отметим, что «процесс доказательства неработоспособности программы» ценится чуть боль- ше, т.к. не позволяет закрывать глаза на обнаруженные проблемы.
Скорее всего, именно из этих рассуждений проистекает неверное пони- мание того, что негативные тест-кейсы должны заканчиваться возникновением сбоев и отказов в приложении. Нет, это не так. Негативные тест-кейсы пытаются вызвать сбои и отказы, но корректно работающее приложение выдерживает это испытание и продолжает работать верно. Также отметим, что ожидаемым результатом негативных тест-кейсов является именно корректное поведение приложения, а сами негативные тест-кейсы считаются пройденными успешно, если им не удалось «поломать» приложе- ние.
- Много «классики тестирования» можно почерпнуть из книги «Искусство тестирова- ния программ» Гленфорда Майерса (издания 1979, 2004, 2011 годов).
Однако большинство критиков отмечает, что эта книга мало подходит для начинающих и куда больше ориентирована на программистов, чем на тестировщиков. Что, впрочем, не умаляет её ценности.
Итак, ещё раз самое важное, что тестирование «приобрело» в 70-е годы: • тестирование позволяет удостовериться, что программа соответствует требованиям; • тестирование позволяет определить условия, при которых программа ведёт себя некор- ректно. В 80-х годах произошло ключевое изменение места тестирования в разработке ПО: вместо одной из финальных стадий создания проекта тестирование стало применяться на протяжении всего цикла разработки (software lifecycle) (также см. описание итерационной инкрементальной модели разработки ПО , что позволило в очень многих случаях не только быстро обнаруживать и устранять проблемы, но даже предсказывать и предотвращать их появление. В этот же период времени отмечено бурное развитие и формализация методологий тестирования и появление первых элементарных попыток автоматизировать тестирование. В 90-х годах произошёл переход от тестирования как такового к более всеобъемлющему процессу, который называется «обеспечение качества (quality assurance )», охватывает весь цикл разработки ПО и затрагивает процессы планирования, проектирования, создания и выполнения тест-кейсов, поддержку имеющихся тест-кейсов и тестовых окружений. Тестирование вышло на качественно новый уровень, который естественным образом привёл к дальнейшему развитию методологий, появлению достаточно мощных инструментов управления процессом тестирования и инструментальных средств автоматизации тестирования, уже вполне похожих на своих нынешних потомков. В 2000 годы нынешнего века развитие тестирования продолжалось в контексте поиска всё новых и новых путей, методологий, техник и подходов к обеспечению качества. Серьёзное влияние на понимание тестирования оказало появление гибких методологий разработки и таких подходов, как «разработка под управлением тестированием (test-driven development , TDD)». Автоматизация тестирования уже воспринималась как обычная неотъемлемая часть большин- ства проектов, а также стали популярны идеи о том, что во главу процесса тестирования следу- ет ставить не соответствие программы требованиям, а её способность предоставить конечному пользователю возможность эффективно решать свои задачи. О современном этапе развития тестирования мы будем говорить на протяжении всего остального материала. Если же отметить вкратце основные характеристики, то получится примерно такой список: гибкие методологии и гибкое тестирование, глубокая интеграция с процессом разработки, широкое использование автоматизации, колоссальный набор технологий и инструментальных средств, кроссфункциональность команды (когда тестировщик и программист во многом могут выполнять работу друг друга).
Так в чем же различие между этими понятиями и почему тестировщиков часто называют специалистами в сфере QA?
Обеспечение качества, в сравнении с тестированием, является более широким понятием. QA помогает оценить правильность протекания технологических процессов на всех этапах разработки ПО для обеспечения его высокого качества.
Кроме тестирования, QA также включает в себя контроль качества, который отвечает за соблюдение предъявляемых к системе требований. Если представить все три термина в виде иерархии, то тестирование окажется частью QC, а QC – частью QA. Таким образом, тестирование заключается в большей степени в проверке работоспособности программного продукта и поиске дефектов, в то время как для QA важно также обеспечить соблюдение стандартов и предотвратить появление ошибок и багов в ПО.
Обобщим:
Тестировщик работает с продуктом как с результатом (т. е. он предполагает, что именно эта версия ПО попадёт в руки конечного пользователя).
QA-инженер работает с продуктом, который находится в процессе создания (т. е. у ПО ещё нет конечной версии).
Зачастую профессии тестировщика ПО и QA-инженера воспринимаются тождественно, однако в выполняемых специалистами задачах существует ряд отличий. Особенности обеспечения качества
Процесс QA включает в себя подготовку плана тестирования, планирование и проведение тестирования, а также управление его результатами. Это помогает определить требования как для разработки ПО, так и для проверки его качества.
В обязанности QA-инженера зачастую входят:
детализация требований к системе;
подготовка тестов и сам процесс тестирования;
поиск и фиксирование дефектов;
контроль исправления багов;
документирование дефектов.
В работе QA-инженера также очень много коммуникации, в том числе с заказчиком. Но не стоит пугаться. В зависимости от компании и проекта часть обязанностей QA-инженер может разделять с бизнес-аналитиками, техническими писателями или тестировщиками, поэтому одна из отличительных черт процесса QA – вовлечённость всей проектной команды.
Исходя из этого, соотношение работы QA-инженера по планированию и по тестированию может сильно отличаться. Что нужно знать о контроле качества?
В QA существует более узкая специализация – это контроль качества. Специалисты этой сферы занимаются анализом результатов тестирования и ликвидацией обнаруженных дефектов. Процедура QC позволяет обеспечить соответствие программного продукта определённому набору критериев и требований, установленных на этапе обеспечения качества.
По сравнению с QA контроль качества требует больше времени и может быть выполнен только после этапа обеспечения качества.
Чтобы процесс контроля качества прошёл максимально эффективно, на проекте нужно:
установить требования и стандарты;
определить перечень мероприятий по контролю качества;
собрать реальные данные и проанализировать их.
Если выявляется отклонение, его корректируют, а процедуру повторяют. QC нужен, чтобы убедиться, что все внесённые изменения дали нужные результаты.
Таким образом, основная задача контроля качества – предоставлять информацию о текущем качестве программного продукта на всех этапах разработки. Что же тогда делает тестировщик?
Профессия тестировщика предполагает составление технической документации, разработку автотестов и их прогон, выявление и анализ ошибок в системе, разработку сценариев тестирования, документирование и многое другое.
Тестирование ПО
В действительности так сложилось, что должности тестировщика и QA-инженера стали синонимами. Даже в документации для заказчика тестировщики обычно записываются как QA Engineers, хотя, как мы уже поняли, выполняемые ими функции отличаются.
Сейчас в большинстве случаев специалисты начинают свою карьеру в IT именно с позиции junior-тестировщика. Это одна из самых лёгких и быстрых точек входа, особенно после прохождения курсов по тестированию ПО. Именно junior-специалисты тестируют разработку по готовым сценариям, в то время как их middle- и senior-коллеги ответственны за разработку планов и тест-кейсов.
Пользователи программного обеспечения испытывают потребности в создании моделей качества программного обеспечения для оценки качества как качественно, так и количественно. Модели качества, которые имеются в настоящее время, в большинстве случаев являются иерархическими моделями на основе критериев качества и связанных с ними показателей (метрик). Все модели качества могут быть разделены на три категории в соответствии с методами, на основе которых они были созданы. К первому виду можно отнести теоретические модели, основанные на гипотезе отношений между переменными качества. Ко второму виду относятся модели «управления данными», основанные на статистическом анализе. И наконец, комбинированная модель, в которой интуиция исследователя используется для определения нужного вида модели, а анализ данных используется для определения констант модели качества
Первая модель качества была предложена МакКолом . Предложенная модель была в основном предназначена для определения полной характеристики качества программного продукта через его различные характеристики. Модель качества МакКола имеет три главных направления для определения и идентификации качества программного обеспечения:
использование (корректность, надежность, эффективность, целостность, практичность);
модификация (тестируемость, гибкость, сопровождаемость – факторы качества важные для разработки новой версии программного обеспечения);
переносимость (мобильность, возможность многократного использования, функциональная совместимость – факторы качества важные для переносимости программного продукта на другие аппаратные и программные платформы).
Факторы качества _________________________________________________ Критерии качества

Второй из основополагающих моделей качества является модель качества Боэма. Модель Боэма имеет недостатки современных моделей, которые автоматически и
качественно оценивают качество программного обеспечения. В сущности, модель Боэма пытается качественно определить качество программного обеспечения заданным набором показателей и метрик. Модель качества Боэма представляет характеристики программного обеспечения в более крупном масштабе, чем модель МакКола. Модель Боэма похожа на модель качества МакКола тем, что она также является иерархической моделью качества, структурированную вокруг высокоуровневых, промежуточных и примитивных характеристик, каждая из которых вносит свой вклад в уровень качества программного обеспечения.
Факторы качества _________________________________________________ Критерии качества

Акроним FURPS, используемый в обозначении модели, обозначает следующие категории требований к качеству ПО:
Functionality (Функциональность) /особенности, возможности, безопасность/;
Usability (Практичность) /человеческий фактор, эргономичность, пользовательская документация/;
Reliability (Надежность) /частота отказов, восстановление информации, прогнозируемость/;
Performance (Производительность) /время отклика, пропускная способность, точность, доступность, использование ресурсов/;
Supportability (Эксплуатационная пригодность) /тестируемость, расширяемость, адаптируемость, сопровождаемость, совместимость, конфигурируемость, обслуживаемость, требования к установке, локализуемость/.
Символ «+» расширяет FURPS модель, добавляя к ней:
ограничения проекта (ограничения по ресурсам, требования к языкам и средствам разработки, требования к аппаратному обеспечению);
интерфейс (ограничения накладываемые на взаимодействие с внешними системами);
требования к выполнению,
физические требования,
требования к лицензированию.
FURPS модель качества , предложенная Грейди и Hewlett Packard, построена схожим образом с моделями МакКола и Боэма, но в отличие от них состоит из двух слоев, первый определяет характеристики, а второй связанные с ними атрибуты. Основной концепцией, лежащей в основе FURPS модели качества, является декомпозиция характеристик программного обеспечения на две категории требований, а именно, функциональные (F) и нефункциональные (URPS) требования. Эти выделенные категории могут быть использованы как в качестве требований к программному продукту, так и в оценке качества ПП. В настоящее время модель FURPS+ широко используется в разработке программного обеспечения и при идентификации требований к разрабатываемой системе целесообразно использование FURPS+ модели в качестве универсального контрольного перечня характеристик ПО.
Карло Гецци и соавторы различают качество продукта и процесса. Согласно модели Гецци к качеству программного обеспечения относят следующие характеристики программного обеспечения: целостность, надежность и устойчивость, производительность, практичность, верифицируемость, сопровождаемость, возможность многократного использования, мобильность, понятность, возможность взаимодействия, эффективность, своевременность реагирования, видимость процесса разработки.
Модель качества Дроми основана на критериях оценки. Модель Дроми стремится оценить качество системы, в то время как каждый программный продукт, имеет качество отличное от других. Модель Дроми помогает в предсказании дефектов ПО и указывает на те свойства ПО, пренебрежение которыми может привести к появлению дефектов. Эта модель основывается на отношениях между характеристиками качества и подхарактеристиками, между свойствами программного обеспечения и характеристиками качества ПО.
ВЦентре обеспечения качества программного обеспечения NASA (Software Assurance Technology Center, SATC) была разработана программа метрик , обеспечивающая оценку рисков проекта, качества продукции и эффективности процессов. Программа SATC рекомендует отдельно отслеживать качество требований, качество программного обеспечения и других продуктов (документации), качество тестирования и качество выполнения процессов. Модель качества SATC определяет набор целей, связанных с программным продуктом и атрибуты процессов в соответствии со структурой модели качества программного обеспечения ISO 9126-1.
Качество программного обеспечения определяется в стандарте ISO 9126-1 как всякая совокупность его характеристик, относящихся к возможности удовлетворять высказанные или подразумеваемые потребности всех заинтересованных лиц.
Модель качества ISO 9126-1 различает понятия внутреннего качества, связанного с характеристиками ПО самого по себе, без учета его поведения; внешнего качества, характеризующего ПО с точки зрения его поведения; и качества ПО при использовании в различных контекстах – того качества, которое ощущается пользователями при конкретных сценариях работы ПО. Для всех этих аспектов качества введены метрики, позволяющие оценить их. Кроме того, для создания надежного ПО существенно качество технологических процессов его разработки
какие же технические навыки нужны, чтобы успешно начать работать тестировщиком?
Знание иностранных языков. Да, это нетехнический навык. Но тем не менее он идёт под номером «ноль». Можете считать это аксиомой: «нет знания английского — нет карьеры в IT». Другие иностранные языки тоже приветствуются, но английский первичен
Уверенное владение компьютером на уровне по-настоящему продвинутого пользователя и желание постоянно развиваться в этой области.
Программирование. Оно на порядки упрощает жизнь любому IT’шнику — и тестировщи- ку в первую очередь. Можно ли тестировать без знания программирования? Да, можно. Можно ли это делать по-настоящему хорошо? Нет. И сейчас самый главный (почти религи- озно-философский) вопрос: какой язык программирования изучать? C/C++/C#, Java, PHP, JavaScript, Python, и т.д. — начинайте с того, на чём написан ваш проект. Если проекта пока ещё нет, начинайте с JavaScript (на текущий момент — самое универсальное решение).
Базы данных и язык SQL. Здесь от тестировщика тоже не требуется квалификация на уров- не узких специалистов, но минимальные навыки работы с наиболее распространёнными СУБД и умение писать простые запросы можно считать обязательными
Понимание принципов работы сетей и операционных систем. Хотя бы на минимальном уровне, позволяющем провести диагностику проблемы и решить её своими силами, если это возможно.
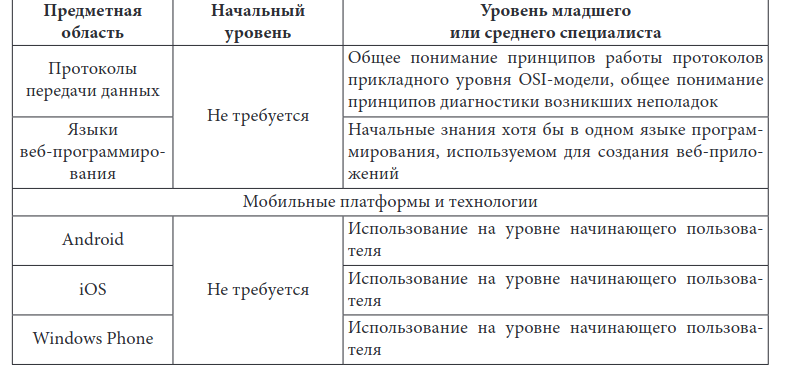
Понимание принципов работы веб-приложений и мобильных приложений. В наши дни почти всё пишется именно в виде таких приложений, и понимание соответствующих тех- нологий становится обязательным для эффективного тестирования.
- повышенная ответственность и исполнительность;
- хорошие коммуникативные навыки, способность ясно, быстро, чётко выражать свои мысли;
- терпение, усидчивость, внимательность к деталям, наблюдательность;
- хорошее абстрактное и аналитическое мышление;
- способность ставить нестандартные эксперименты, склонность к исследовательской дея- тельности.
Все навыки здесь условно разделены на три группы: • Профессиональные — это именно «тестировщицкие», ключевые навыки, отличающие тес- тировщика от других IT-специалистов. • Технические — это общие навыки в области IT, которыми тем не менее должен обладать и тестировщик. • Личностные — в русском языке термин «soft skills» часто переводят как «навыки межлич- ностного общения», но исходный термин несколько шире.
| Процесс тестирования ПО |
|---|
| Глубокое понимание стадий процесса тестирования,их взаимосвязи и взаимовлияния, умение планировать собственную работу в рамках полученного задания в зависимости от стадии тестирования |
| Процессразработки ПО |
|---|
| Общее понимание моделей разработки ПО, их связи с тестированием, умение расставлять приоритеты в собственной работе в зависимости от стадии развития проекта |
| Анализ требований |
|---|
| Умение определять взаимосвязи и взаимозависимость между различными уровнями и формами представления требований, умение формулировать вопросы с целью уточнения неясных моментов |
| Тестирование требований |
|---|
| Знание свойств хороших требований и наборов требований, умение анализировать требования с целью выявления их недостатков, умение устранять недостатки в требованиях,умение применять техники повышения качества требований |
| Управление требованиями |
|---|
| Общее понимание процессов выявления, документирования, анализа и модификации требований |
| Бизнес-анализ |
|---|
| Общее понимание процессов выявления и документирования различных уровней и форм представления требований |
| Создание плана тестирования |
|---|
| Общее понимание принципов планирования в контексте тестирования, умение использовать готовый тест-план для планирования |
| собственной работы |
| Создание стратегии тестирования |
|---|
| Общее понимание принципов построения стратегии тестирования, умение использовать готовую стратегию для планирования собственной работы |
| Оценка трудозатрат |
|---|
| Общее понимание принципов оценки трудозатрат,умение оценивать собственные трудозатраты при планировании собственной работы |
| Создание чек-листов |
|---|
| Твёрдое умение использовать техники и подходы к проектированию тестовых испытаний, умение декомпозировать тестируемые объекты и поставленные задачи, умение создавать чек-листы |
| Создание тест-кейсов |
|---|
| Твёрдое умение оформлять тест-кейсы согласно принятым шаблонам, умение анализировать готовые тест-кейсы, обнаруживать и устранять имеющиеся в них недостатки |
| Управление тест-кейсами |
|---|
| Общее понимание процессов создания, модификации и повышения качества тест-кейсов |
| Функциональное и доменное тестирование |
|---|
| Знание видов тестирования, твёрдое умение использовать техники и подходы к проектированию тестовых испытаний, умение создавать чек-листы и тест-кейсы, умение создавать отчёты о дефектах |
 |




Андерклокинг — снижение частоты работы оборудования.
Баг (дефект) — недостаток компонента или системы, который может привести к отказу определенной функциональности.
Приоритет багов — важность той или иной ошибки в ПО:
Trivial — косметическая малозаметная проблема.
Minor — очевидная, незначительная проблема.
Major — значительная проблема.
Critical — проблема, нарушающая работу c ключевыми функциями ПО.
Blocker — проблема, нарушающая функционирование ПО.
Баг-репорт — документ, описывающий ситуацию или последовательность действий приведшую к некорректной работе объекта тестирования, с указанием причин и ожидаемого результата.
Валидация — определение соответствия разрабатываемого ПО ожиданиям и потребностям пользователя, требованиям к системе.
Верификация — процесс оценки системы или её компонентов с целью определения удовлетворяют ли результаты текущего этапа разработки условиям, сформированным в начале этого этапа. Спецификация — детальное описание того, как должно работать ПО.
Система отслеживания ошибок (англ. bug tracking system) — программа учета и/или контроля багов:
Atlassian JIRA
Bugzilla
YouTrack
Redmine
etc.
Тестирование — процесс проверки соответствия заявленных к продукту требований и реально реализованной функциональности, осуществляемый путем наблюдения за его работой в искусственно созданных ситуациях и на ограниченном наборе тестов, выбранных определенным образом.
Обеспечение качества (Quality Assurance, QA) — совокупность мероприятий, охватывающих все технологические этапы разработки, выпуска и эксплуатации программного обеспечения
Отладка (англ.Debugging) — процесс, позволяющий получить программное обеспечение, функционирующее с требующимися характеристиками в заданной области входных данных.
Ошибка (англ.Error) – действие, которое порождает неправильный результат.
Сбой (англ.Failure) – несоответствие фактического результата работы компонента или системы ожидаемому результату.
Классификация по типу тестирования:
Мобильное тестирование — тестирование мобильных приложений.
Консольное тестирование — тестирование приложений предназначенных для консолей.
Web-тестирование (Браузерное тестирование) — тестирование браузерных приложений.
Классификация по запуску кода на исполнение: Статическое тестирование (англ.Static testing) — тестирование без запуска кода на исполнение. Динамическое тестирование (англ. Dynamic testing) — тестирование с запуском кода на исполнение.
Классификация по доступу к коду и архитектуре ПО:
Черный ящик (англ. Black box) — тестировщику не известно как устроена тестируемая система. Белый ящик (англ. White box) — тестировщику известно все детали реализации тестируемой системы. Серый ящик (англ. Grey box) — тестировщику известно только некоторые особенности устройства тестируемой системы.
Классификация по степени автоматизации: Ручное тестирование (англ. Manual testing) — тестирование ПО будучи его пользователем. Автоматизированное тестирование (англ. Automated testing) — тестирование ПО при помощи специальных программ.
Классификация по принципу работы с приложением: Позитивное тестирование (англ. Positive testing) — тестирование ПО на то, как оно должно работать. Негативное тестирование (англ. Negative testing) — тестирование ПО на то, как оно не должно работать.
Классификация по уровню детализации приложения: Интеграционное тестирование — тестирование взаимодействия и связей нескольких компонентов приложения. Системное тестирование — это тестирование всего приложения от начала и до конца. Модульное тестирование — тестирование на уровне отдельного функционального компонента приложения.
Классификация по целям и задачам: Функциональное тестирование — проверка корректности работы функциональности приложения.
Нефункциональное тестирование — проверка нефункциональных особенностей приложения (удобство использования, совместимость, производительность, безопасность).
Инсталляционное тестирование — проверка протекания стадии инсталляции (установки) приложения. Регрессионное тестирование — проверка на наличие багов, вызванных изменениями в приложении.
Повторное тестирование — выполнение тест-кейсов, которые ранее обнаружили дефекты, с целью подтверждения устранения дефектов.
Приёмочное тестирование — тестирование, направленное на проверку приложения с точки зрения конечного пользователя/заказчика
Тестирование удобства использования — тестирование, направленное на исследование того, насколько конечному пользователю понятно, как работать с продуктом, а также на то, насколько ему нравится использовать продукт.
Тестирование доступности — тестирование, направленное на исследование пригодности продукта к использованию людьми с ограниченными возможностями
Тестирование интерфейса — тестирование, направленное на проверку интерфейсов приложения или его компонентов.
Тестирование безопасности — тестирование, направленное на проверку способности приложения противостоять злонамеренным попыткам получения доступа к данным или функциям
Тестирование интернационализации — тестирование, направленное на проверку готовности продукта к работе с использованием различных языков и с учётом различных национальных и культурных особенностей.
Тестирование локализации — тестирование, направленное на проверку корректности и качества адаптации продукта к использованию на том или ином языке с учётом национальных и культурных особенностей.
Тестирование совместимости — тестирование, направленное на проверку способности приложения работать в указанном окружении (браузер, мобильное ус-во и т.д.).
Тестирование данных и баз данных — тестирование, направленное на исследование таких характеристик данных, как полнота, непротиворечивость, целостность, структурированность и т.д.
Тестирование использования ресурсов — совокупность видов тестирования, проверяющих эффективность использования приложением доступных ему ресурсов и зависимость результатов работы приложения от количества доступных ему ресурсов.
Сравнительное тестирование — тестирование, направленное на сравнительный анализ преимуществ и недостатков разрабатываемого продукта по отношению к его основным конкурентам.
Демонстрационное тестирование — формальный процесс демонстрации заказчику продукта с целью подтверждения, что продукт соответствует всем заявленным требованиям.
Избыточное тестирование — тестирование приложения со всеми возможными комбинациями всех возможных входных данных во всех возможных условиях выполнения.
Тестирование надёжности — тестирование способности приложения выполнять свои функции в заданных условиях.
Тестирование восстанавливаемости — тестирование способности приложения восстанавливать свои функции и заданный уровень производительности, а также восстанавливать данные в случае возникновения критической ситуации.
Тестирование отказоустойчивости — тестирование, заключающееся в эмуляции или реальном создании критических ситуаций с целью проверки способности приложения задействовать механизмы, предотвращающие нарушение работоспособности, производительности и повреждения данных.
Тестирование производительности — исследование показателей скорости реакции приложения на внешние воздействия при различной по характеру и интенсивности нагрузке.
Нагрузочное тестирование — исследование способности приложения сохранять заданные показатели качества при нагрузке в допустимых пределах и некотором превышении этих пределов/
Тестирование масштабируемости — исследование способности приложения увеличивать показатели производительности в соответствии с увеличением количества доступных приложению ресурсов.
Объёмное тестирование — исследование производительности приложения при обработке различных (как правило, больших) объёмов данных.
Стрессовое тестирование — исследование поведения приложения при нештатных изменениях нагрузки, значительно превышающих расчётный уровень.
Конкурентное тестирование — исследование поведения приложения в ситуации, когда ему приходится обрабатывать большое количество одновременно поступающих запросов, что вызывает конкуренцию между запросами за ресурсы (базу данных, память, канал передачи данных, дисковую подсистему и т.д.)
Фокус-тест (англ. Focus test) — тестирование, проводимое с целью получения первичной реакции игроков. Необходимо для оценки удобства использования и того, как продукт принимается целевой аудиторией или сторонними людьми.
Failure — сбой (причём не обязательно аппаратный) в работе компонента, всей программы или системы.
UX (англ. User eXperience — опыт пользователя) — ощущение, испытываемое пользователем во время использования цифрового продукта.
UI (англ. User Interface — пользовательский интерфейс) — это инструмент, позволяющий осуществлять взаимодействие «пользователь — приложение».
Анализ граничных значений (англ. Boundary Value Analysis — BVA). Анализ граничных значений может быть применен к полям, записям, файлам, или к любого рода сущностям имеющим ограничения.
Дымовое тестирование (англ. Smoke test) — короткий цикл тестов для подтверждения, что после сборки кода (нового или исправленного) приложение стартует и выполняет основные функции.
Исследовательское (ad-hoc) тестирование — это разработка и выполнения тестов в одно и то же время, что является противоположностью сценарного подхода.
Конфигурационное тестирование (англ. Configuration Testing) — специальный вид тестирования, направленный на проверку работы программного обеспечения при различных конфигурациях системы (заявленных платформах, поддерживаемых драйверах, при различных конфигурациях компьютеров и т.д.)
Матрица соответствия требований (англ. Traceability matrix) — это двумерная таблица, содержащая соответсвие функциональных требований (functional requirements) продукта и подготовленных тестовых сценариев (test cases).
Операционное тестирование (англ. Release Testing). Даже если система удовлетворяет всем требованиям, важно убедиться в том, что она удовлетворяет нуждам пользователя и выполняет свою роль в среде своей эксплуатации, как это было определено в бизнес модели системы.
Предугадывание ошибки (англ. Error Guessing — EG). Это когда тест аналитик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать» при каких входных условиях система может выдать ошибку.
Причина / Следствие (англ. Cause/Effect — CE). Это, как правило, ввод комбинаций условий (причин), для получения ответа от системы (Следствие).
Санитарное тестирование — это узконаправленное тестирование достаточное для доказательства того, что конкретная функция работает согласно заявленным в спецификации требованиям.
Серьезность (англ. Severity) — это атрибут, характеризующий влияние дефекта на работоспособность приложения.
Стадии разработки ПО — это этапы, которые проходят команды разработчиков ПО, прежде чем программа станет доступной для широко круга пользователей.
Пре-альфа (англ. Pre-alpha) — начальная стадия разработки. Период времени со старта разработки до выхода стадии Альфа. Также так называются программы, прошедшие стадию разработки, для первичной оценки функциональных возможностей в действии.
Альфа-тестирование (англ. Alpha testing) — имитация реальной работы с системой штатными разработчиками, либо реальная работа с системой потенциальными пользователями/заказчиком на ранней стадии разработки продукта, но в некоторых случаях может применяться для законченного продукта в качестве внутреннего приёмочного тестирования.
Бета-тестирование (англ. Beta testing) — интенсивное использование почти готовой версии продукта с целью выявления максимального числа ошибок в его работе для их последующего устранения перед окончательным выходом (релизом) продукта на рынок, к массовому потребителю.
Релиз-кандидат или RC (англ. Release candidate), Пре-релиз, иногда «гамма-версия» — стадия-кандидат на то, чтобы стать стабильной.
Релиз или RTM (англ. Release to manufacturing — промышленное издание) — издание продукта, готового к тиражированию.
Пост-релиз или Post-RTM (англ. Post-release to manufacturing) — издание продукта, у которого есть несколько отличий от RTM и помечается как самая первая стадия разработки следующего продукта.
Таблица принятия решений (англ. Decision table) — инструмент для упорядочения сложных бизнес требований, которые должны быть реализованы в продукте.
Тест-дизайн (англ. Test design) — это этап процесса тестирования ПО, на котором проектируются и создаются тестовые случаи (тест кейсы).
Тест-план (англ. Test Plan) — это документ, описывающий весь объем работ по тестированию, а также оценки рисков с вариантами их разрешения.
Тестирование взаимодействия (англ. Interoperability Testing) — это функциональное тестирование, проверяющее способность приложения взаимодействовать с одним и более компонентами или системами.
Тестирование сборки (англ. Build Verification Test) — тестирование направленное на определение соответствия, выпущенной версии, критериям качества для начала тестирования.
Тестирование пользовательского интерфейса (англ. UI Testing) — тестирование, выполняемое с целью определения, удобен ли некоторый искусственный объект (такой как веб-страница, пользовательский интерфейс или устройство) для его предполагаемого применения.
Тестовый случай (англ. Test Case) — это артефакт, описывающий совокупность шагов, конкретных условий и параметров, необходимых для проверки реализации тестируемой функции или её части.
Чек-лист (англ. Check list) — это документ, описывающий что должно быть протестировано.
Эквивалентное Разделение (англ. Equivalence Partitioning — EP). Как пример, у вас есть диапазон допустимых значений от 1 до 10, вы должны выбрать одно верное значение внутри интервала, скажем, 5, и одно неверное значение вне интервала — 0.
Z-конфликт (англ. Z-fighting) — наложение текстур друг на друга.
Оверклокинг (англ. Overclocking) — процесс увеличения частоты (и напряжения) компонента компьютера сверх штатных режимов с целью увеличения скорости его работы.
Тестирование Дот Ком

Наверное, это самая популярная книга по тестированию на русском языке, которая отлично подходит для начинающих тестировщиков.
Довольно легкий слог повествования и простая подача материала. С этой книгой вы познакомитесь с необходимой начальной терминологией, чтобы быть «в теме» среди отдела качества разработки ПО. Также она поможет понять, что собственно требуется от тестировщика в решении тех или иных задач. Приведены примеры для простоты усвоения материала.
The Self-Taught Software Tester
Чхави Радж Досадж, “The Self-Taught Software Tester A Step By Step Guide to Learn Software Testing Using Real-Life Project”

Эта книга – отличное введение в тестирование программного обеспечения для любого читателя. Информация представлена грамотно. Следуя примерам в книге, вы почувствуете, что проходите практическое обучение на реальном проекте.
Если ваша цель – стать тестировщиком программного обеспечения, эта книга станет вашим секретным оружием в становлении первоклассным специалистом.
Software testing Рон Паттон, “Software testing”

Еще одна по-настоящему очень полезная книга для начинающих тестировщиков. В ней вы найдете довольно подробную и очень популярно описанную теоретическую базу тестирования. В довесок, приведено множество примеров для лучшего усвоения материала. Читателя завлечет хороший и доступный язык повествования.
Introducing to Software Testing
Пол Амманн и Джефф Оффатт, “Introducing to Software Testing”

Возможно, вас заинтересует данная книга, она затрагивает множество концепций направления тестирования, такие как автоматизация, различные тест дизайны и в целом управление процессом тестирования. Конечно, она больше ориентирована на продолжающих свой путь тестировщиков, которые хотят попробовать себя в автоматизации и больше проникнуться техническими аспектами профессии, но каждый найдет в этой книге свое. Книга хорошо структурирована и полна множеством технических аспектов.
Тестирование программного обеспечения
Сэм Канер, Джек Фолк, Енг Кек Нгуен, «Тестирование программного обеспечения. Фундаментальные концепции менеджмента бизнес-приложений».

Данный труд предназначен в первую очередь для продолжающих специалистов, которые хотят познакомиться с теорией тестирования. Написана сложным языком, довольно объемная и требует внимательности при чтении. Затрагивает все концепции тестирования. Прочитав её, вы поднимите свой уровень в области качества ПО.
В книге много примеров, включая реальные кейсы, что делает книгу суперполезной и практичной.
Искусство тестирования программ
Гленфорд Майерс, Том Баджетт, Кори Сандлер, «Искусство тестирования программ»

Одна из основополагающих книг по тестированию, можно сказать, классическая литература в данной области. Для читающего эта книга станет исчерпывающим руководством по всем типам тестирования – от тестирования веб приложений до тестирования безопасности, тестирования совместимости и автоматизации тестирования.
Тут детально рассмотрена психология тестирования и тестирование в гибкой среде, показаны наиболее эффективные способы обеспечения качества для программных продуктов.
Complete Guide to Test Automation Арнон Аксельрод, Complete Guide to Test Automation

В первую очередь эта книга будет полезна для специалистов, которые намерены развиваться в сторону автоматизации тестирования.
Это надежное и подробное руководство, которое поможет создавать и поддерживать автоматизацию на должном уровне. Охватывает все важные темы, а также дает примеры распространенных сценариев в проектах автоматизации.
Идеальное программное обеспечение

Эту книгу следует обязательно прочитать всем специалистам в области разработки и тестирования программного обеспечения. Автор хорошо повествует о ценности тестирования, подводных камнях и общих подходах в разработке и управлению тестированием. Хорошо описаны моменты, на чем тестировщикам следует сосредоточиться, когда дело касается софт скиллов и общения внутри и за пределами команды.
Эта книга – реальное напоминание о том, зачем нужны тестировщики и почему тестировщики никогда не могут быть заменены компьютерами.
A Practitioner’s Guide to Software Test Design
Ли Коупленд, «A Practitioner’s Guide to Software Test Design»

Еще одна «библия тестировщика», обязательна к прочтению. В этой книге подробно, поэтапно и с понятными примерами дается описание различных техник проектирования тестов. Автор делится огромным количеством ценных советов, которые помогут улучшить вашу работу уже в процессе чтения. Книга с конкретным изложением, без лишней воды и философии, все четко и по делу.
Managing the Testing Process
Рекс Блэк, “Managing the Testing Process: Practical Tools and Techniques for Managing Hardware and Software Testing”.
 Хорошая книга для более глубокого понимания управления процессом тестирования, отлично подойдет разработчикам, тестировщикам и менеджерам тестирования. В книге представлено прямое описание того, как нужно правильно управлять процессом тестирования. Рассмотрены роли в этом управлении и его обязанности. В качестве повышения уровня компетенций менеджмента в тестировании, книга очень хороша.
Хорошая книга для более глубокого понимания управления процессом тестирования, отлично подойдет разработчикам, тестировщикам и менеджерам тестирования. В книге представлено прямое описание того, как нужно правильно управлять процессом тестирования. Рассмотрены роли в этом управлении и его обязанности. В качестве повышения уровня компетенций менеджмента в тестировании, книга очень хороша.





Понимание принципов работы сетей и операционных систем.
Что такое операционная система
Это первое, о чем нужно задуматься, если вы решили разобраться, как работают операционные системы. ОС представляют собой набор программного обеспечения. Это ПО управляет компьютерным оборудованием и предоставляет техническую базу для программ. А ещё они управляют вычислительными ресурсами и обеспечивают защиту. Главное, что у них есть, – это доступ к управлению компонентами компьютера.
Файловая система, планировщик и драйверы – всё это основные инструменты работы ОС.
Существует три ключевых элемента операционной системы:
Кроме того, есть два основных принципа проектирования операционных систем:
Теперь подробнее разберём глобальные концепции, которые помогут сформировать понимание того, как работают операционные системы.
Процессы и управление
Процесс – не что иное, как исполнение программы. Так как программа записана в виде последовательности действий в текстовый файл, процессом она становится только при запуске.
Загруженная в память программа может быть условно разделена на четыре части: стек, кучу, контекст и данные.
Когда процесс выполняется, он проходит через разные состояния. Эти этапы могут различаться в разных операционных системах.
Общая картина выглядит так:
Немного терпения: мы уже близки к пониманию того, как работают операционные системы ;)
Блок управления процессов (Process Control Block) – это структура данных, поддерживаемая операционной системой для каждого процесса. PCB имеет идентификатор PID. Именно PCB хранит всю информацию, необходимую для отслеживания процесса.
Потоки и параллелизм
Поток (нить, thread) – это ход исполнения программы. Он также имеет свой program counter, переменные, стек.
Потоки одной программы могут работать с одними данными, а взаимодействовать между собой через код.
Поток – это легковесный процесс. Вместе они обеспечивают производительность приложений и ОС за счет параллелизма на уровне программы.
Каждый поток относится к какому-то процессу и не может существовать без него. Сегодня потоки широко применяются в работе серверов и многопроцессорных устройств с общей памятью.
Чем хороши потоки:
Потоки имеют два уровня реализации:
В первом случае ядро управления потоками ничего не знает о существовании потоков вообще. А библиотека потоков просто содержит код для создания и уничтожения потоков, а также передачи сообщений и данных между ними для планирования выполнения потоков и сохранения (восстановления) контекстов потоков.
Во втором случае ядро выполняет создание потоков, а ещё планирование и управление в пространстве ядра. Заметим, что потоки ядра обычно медленнее, чем потоки пользователей.
Планирование
Планировщик – это часть менеджера процессов, которая ответственна за переключение между процессами и выбор очереди по какой-либо стратегии.
ОС поддерживает все блоки управления процессом (PCB) в очередях планирования процесса:
ОС может использовать разные методы реализации для управления очередями (FIFO, Round Robin, Priority). Планировщик ОС определяет, когда и как перемещать процессы между готовыми и запущенными очередями (могут иметь только одну запись на ядро процессора в системе). На приведенной выше диаграмме он был объединен с процессором.
Модели состояния делятся на активные и неактивные:
Переключение контекста – это механизм сохранения (в PCB) и восстановления контекста процессора с ранее запущенного промежутка времени. При использовании этого метода, коммутатор контекста позволяет использовать один процессор для нескольких действий одновременно. Кстати, контекстное переключение является неотъемлемой частью многозадачной операционной системы.
Когда планировщик переключает процессор с одного процесса на другой, состояние из текущего запущенного процесса сохраняется в блоке управления. Затем состояние для следующего процесса загружается из своего PCB в регистры процессора. Только потом второй процесс может быть запущен.
При переключении следующая информация сохраняется для последующего использования: счетчик программы, информация планировщика, значение регистра базы и лимита, используемый в настоящее время регистр, измененное состояние, информация о состоянии ввода и вывода, учетная информация.
Управление памятью
Ещё одна важная часть – та, что отвечает за все операции по управлению первичной памятью. Существует менеджер памяти, который обрабатывает все запросы на получение памяти и высвобождение. Он же следит за каждым участком памяти, независимо от того, занят он или свободен. И он же решает, какой процесс и когда получит этот ресурс.
Адресное пространство процесса – набор логических адресов, к которым программа обращается в коде. Например, если используется 32-битная адресация, то допустимые значения варьируются от 0 до 0x7fffffff, то есть 2 Гб виртуальной памяти.
Операционная система заботится о том, чтобы сопоставить логические адреса с физическими во время выделения памяти программе. Нужно также знать, что существует три типа адресов, используемых в программе до и после выделения памяти:
Виртуальные и физические адреса одинаковы как в процессе загрузки, так и во время компиляции. Но они начинают различаться во время исполнения.
Набор всех логических адресов, которые создала программа, называется логическим адресным пространством. Набор всех физических адресов, соответствующих этим логическим адресам, называется физическим адресным пространством.
Хотите разобраться подробнее в том, как работают операционные системы? Посмотрите соответствующие книги в нашем Телеграм-канале.
Межпроцессорное взаимодействие
Существует два типа процессов: независимые и взаимодействующие. На независимые не оказывается влияние процессов сторонних, в отличие от взаимодействующих.
Можно подумать, что процессы, которые работают независимо, выполняются эффективнее, но зачастую это не так. Использование кооперации может повысить скорость вычислений, удобство и модульность программ.
Межпроцессная коммуникация (IPC) – это механизм, который позволяет процессам взаимодействовать друг с другом и синхронизировать действия. Связь между этими процессами может рассматриваться как сотрудничество.
Процессы могут взаимодействовать двумя способами: через общую память или через передачу сообщений.
Метод использования общей памяти
Допустим, есть два процесса: исполнитель (производитель) и потребитель. Один производит некоторый товар, а второй его потребляет. Эти два процесса имеют общее пространство или ячейку памяти, известную как «буфер». Там хранится элемент, созданный исполнителем, оттуда же потребитель получает этот элемент.
Однако у этих версий есть как минимум две значимые проблемы: первая известна как проблема безграничного буфера: исполнитель может продолжать создавать элементы без ограничений на размер буфера. Вторая заключается в том, что исполнитель, заполнив буфер, переходит в режим ожидания.
В задаче с ограниченным буфером у исполнителя и потребителя будет общая память. Если общее количество произведенных товаров равно размеру буфера, то исполнитель будет ждать их потребления.
Аналогично потребитель сначала проверит наличие товара, и если ни один элемент не будет доступен, придётся ждать его освобождения.
Метод анализа сообщений
С помощью этого метода процессы взаимодействуют друг с другом без использования общей памяти. Допустим, есть два процесса, p1 и p2, которые хотят взаимодействовать друг с другом. Они работают следующим образом:
Размер сообщения может быть фиксированным или переменным. Проектировщикам ОС проще работать с сообщениями фиксированного размера, а программистам – переменного. Стандартное сообщение состоит из двух частей – заголовка и тела.
Управление вводом и выводом
Одной из важнейших задач операционной системы является управление различными устройствами ввода и вывода вроде мыши, клавиатуры, дисководов, etc.
Система ввода и вывода принимает запрос приложения на ввод или вывод данных, а затем отправляет его на соответствующее физическое устройство. После возвращает приложению полученный ответ. Устройства ввода и вывода можно разделить на две категории:
ЦПУ должен иметь способ передачи информации на устройство ввода-вывода и обратно. И есть три способа сделать это:
Особые, неуниверсальные инструкции процессора, внедренные специально для контроля устройств ввода-вывода. Они позволяют отправлять данные на устройство и считывать их оттуда.
Когда используется ввод-вывод с отображением памяти, одно и то же адресное пространство разделяется памятью и устройствами ввода-вывода. Устройство подключается непосредственно к ячейкам памяти так, чтобы можно было передавать блок данных без применения ЦПУ.
Медленные устройства, такие как клавиатуры, генерируют прерывания ЦПУ после передачи каждого байта. Если бы быстрые устройства работали похожим образом, то ОС бы тратила большую часть времени впустую, на обработку этих прерываний. Поэтому для снижения нагрузки обычно используется прямой доступ к памяти (DMA).
Это означает, что ЦПУ предоставляет модулю ввода и вывода полномочия для чтения или записи в память. Сам модуль управляет обменом данными между основной памятью и устройством ввода-вывода. ЦПУ участвует в начале и конце передачи, а прерывается только после полной передачи блока.
Организация прямого доступа к памяти требует специального оборудования, называемого контроллером DMA (DMAC). Он управляет передачей данных и доступом к системной шине. Контроллеры запрограммированы с указателями источника и места назначения, счетчиками для отслеживания количества переданных байтов и прочими настройками.
Виртуализация
Технология, которая позволяет создавать несколько сред или выделенных ресурсов из единой физической аппаратной системы называется виртуализация
Программное обеспечение, гипервизор, напрямую подключается к этой аппаратной системе и позволяет разбить ее на отдельные, безопасные среды – виртуальные машины. По идее, гипервизор должен аппаратные ресурсы между виртуальными машинами так, чтобы процессы выполнялись быстрее.
Физическая машина с гипервизором называется хостом, а виртуальные машины, которые используют ресурсы данного хоста – гостями. Для них ангаром ресурсов являются процессор, память, хранилище. Для получения доступа к этим ресурсам операторы управляют виртуальными экземплярами.
В идеале, все связанные виртуальные машины управляются с помощью единой веб-консоли управления виртуализацией. Она нужна, чтобы ускорять работу. Виртуализация позволяет определить, сколько вычислительной мощности и памяти выделять виртуальным машинам. Кроме того, так как виртуальные машины технически не связаны между собой, это повышает безопасность сред.
Проще говоря, виртуализация создает дополнительные мощности для выполнения процессов.
Типы виртуализации
Система файловой дистрибуции
Распределенная файловая система – это клиентское или клиент-серверное приложение, которое позволяет получать и обрабатывать данные. Они хранятся на сервере, как если бы они находились на персональном компьютере. Когда пользователь запрашивает файл, сервер отправляет ему копию запрашиваемого файла, который кэшируется на компьютере пользователя во время обработки данных, а затем возвращается на сервер.
Бывает так, что за одними и теми же данными одновременно обращаются сразу несколько пользователей. Для этих целей сервер должен иметь механизм организации обновлений, чтобы клиент всегда получал самую актуальную версию данных. Распределенные файловые системы обычно используют репликацию файлов или баз данных для защиты от сбоев.
Сетевая файловая система Sun Microsystems (NFS), Novell NetWare, распределенная файловая система Microsoft и DFS от IBM являются примерами распределенных файловых систем.
Распределенная общая память
Распределенная общая память (DSM) – это компонент управления ресурсами распределенной операционной системы. В DSM доступ к данным осуществляется из общего пространства, аналогично способу доступа к виртуальной памяти. Данные перемещаются между дополнительной и основной памятью, а также между разными узлами. Изменения прав собственности происходят, когда данные перемещаются с одного узла на другой.
Преимущества распределенной общей памяти:
Облачные вычисления
Всё больше процессов переходит в облако. По сути, облачные вычисления – это своего рода аутсорсинг компьютерных программ. Используя облачные вычисления, пользователи могут получать доступ к программному обеспечению и приложениям из любого места. Это означает, что им не нужно беспокоиться о таких вещах, как хранение данных и питание компьютера.
Традиционные бизнес-приложения всегда были очень сложными, дорогими в обслуживании – нужна команда экспертов для установки, настройки, тестирования, запуска, защиты и обновления. Это одна из причин, почему стартапы проигрывают корпорациям.
Используя облачные вычисления, вы передаёте ответственность за аппаратное и программное обеспечение опытным специалистам, таким как Salesforce и AWS. Вы платите только за то, что вам нужно, апгрейд платежного плана производится автоматически по мере ваших потребностей, а масштабирование системы протекает без особых сложностей.
Приложения на базе облачных вычислений могут работать эффективнее, дольше и стоить дешевле. Уже сейчас компании используют облачные приложения для множества приложений, таких как управление отношениями с клиентами (CRM), HR, учет и так далее.
Итоги
В заключение хочется ещё раз вернуться к тому, зачем вообще разбираться в том как работают операционные системы. Операционная система – это «мозг», который управляет входными, обрабатываемыми и выходными данными. Все остальные компоненты также взаимодействуют с операционной системой. Понимание того, как работают операционные системы, прояснит некоторые детали и в других компьютерных науках, ведь взаимодействие с ними организуется именно средствами ОС.