С течением времени оптимизация сайтов для поисковых систем меняется. Поисковые машины улучшаются, добавляя новые алгоритмы поиска. И список критериев, которые помогут поднять страницу в ТОП становится все длиннее.
Чтобы продвинуть свой сайт к верхушке списка, необходимы глубокие знания SEO оптимизации. Для повышения доверия к сайту, оптимизировать его нужно полностью. Поисковые системы всегда стремятся сделать выдачу результатов более качественной и релевантной поисковому запросу. Чтобы предлагаемые сайты соответствовали запросу пользователя и были самыми полезными, привлекательным, удобным в пользовании.
Что такое SEO-продвижение сайта?
Аббревиатура SEO расшифровывается как Search Engine Optimization, в переводе на русский - оптимизация для поисковых систем. Она имеет много синонимов: “Поисковое продвижение”, “Продвижение в поиске”, “Поисковая раскрутка”, “Раскрутка сайта” и т.д.
В целом, это определенные действия, которые предпринимаются, чтобы страницы сайта оказывались на высоких позициях в поисковых системах по целевым запросам.
Техническая оптимизация сайта
Техническая, или о внутренней, оптимизация. Она значительно влияет на правильную индексацию и ранжирование и ещё помогает обезопасить сайт от утечки непубличных данных в выдачу поисковых систем.
В первой части разберём
Оптимизацию URL-адресов страниц сайта.
Поиск и устранение «зеркал» сайта.
Корректировку robots.txt.
Определение и устранение дублей страниц.
Работу сайта при отключенном JavaScript.
Обработку ошибки 404.
Оптимизация URL-адресов страниц сайта
Для правильной индексации важно, чтобы страницы сайта отражали его структуру. Поэтому уровни вложенности URL должны соответствовать уровню вложенности страниц относительно корня сайта. Но не стоит впадать в крайность и делать адреса c пятью уровнями вложенности и более.
При формировании адресов следует придерживаться простых правил:
Исключить из адресов все специальные символы вроде «?», «=», «&».
Использовать цифры в псевдостатических адресах можно без ограничений.
В качестве разделителя слов в адресе лучше использовать символ «-» (дефис).
Использовать в адресах транслитерированные ключевые слова, которые в точности соответствуют контенту страницы. Использовать в адресах только строчные латинские символы, не кириллицу. Возьмём в качестве примера интернет-магазин мебели. В каталоге магазина существует раздел «Угловые диваны». Правильный URL-адрес этого раздела выглядит так: domain.by/catalog/uglovye-divany/.
Частая проблема, особенно среди интернет-магазинов, — когда одна страница доступна по нескольким адресам. Например, для одного товара создают несколько адресов в зависимости раздела, в котором он расположен. С точки зрения поисковых систем такие страницы считаются дублями и негативно влияют на индексацию.
Некоторые решают эту проблему при помощи тега link с атрибутом rel=”canonical”. Но этот тег служит рекомендательным и не всегда учитывается поисковыми системами. Лучше задать универсальный адрес. Например, адрес карточки товара для условного дивана «Амстердам» будет выглядеть так: *domain.by/product/amsterdam.
Внедрение данного алгоритма формирования псевдостатических адресов для страниц карточек товаров позволит:
Избежать чрезмерного уровня вложенности в структуре URL и положительно скажется на индексации. Устранит риск возникновения дублей. Важно: после внедрения или корректировки псевдостатической адресации со всех старых URL на новые настройте редиректы 301. При переходе на страницы по новым адресам сервер не должен выдавать промежуточный код ответа 301. В ответ на запрос страницы сервер должен выдавать содержимое страницы с кодом ответа 200 без перенаправлений.
Поиск и устранение «зеркал» сайта Поисковые системы не любят, когда у сайта есть «зеркала», то есть точные копии, размещённые на других доменах.
«Зеркала» обычно возникают по следующим причинам:
Когда несколько доменов привязаны к одному физическому сайту (набору файлов на хостинге). Когда есть служебные домены, автоматически генерируемые хостингом. Когда домен с указанием порта (например, domain.ru:8080). Из-за IP-адреса (например, если сайт доступен по IP 192.168.1.1). Несколько шагов, которые помогут обнаружить дубли:
Несколько шагов, которые помогут обнаружить дубли:
Проверьте сайт с помощью сервисов для поиска «зеркал» и индексированных доменов. Определите IP-адрес сайта (например, в 2ip). Выгрузите источники по страницам входа из «Яндекс.Метрики» в таблицу Excel (ставим точность 100% и временной интервал около десяти лет).
Первый столбец данных из «Яндекс.Метрики» нужно скопировать в отдельную вкладку и объединить с данными, которые мы получили в ходе первых двух шагов. Затем в таблице с помощью функции «Заменить на» удалите протоколы HTTP и HTTPS и префиксы WWW. Затем из списка нужно удалить дубли.
Найти зеркало можно с помощью поиска по текстовым фрагментам. Для этого необходимо ввести часть текста с сайта (пять-восемь слов, идущих подряд) в поисковую строку и заключить их в кавычки.
Технические факторы ранжирования
Сайт, который будет продвигаться в поиске, в первую очередь должен соот- ветствовать всем техническим требованиям и рекомендациям поисковых систем. С каждым годом продвигать сайты становится всё сложнее, алгоритмы поисковых систем становятся всё более изощрёнными. Часть требований поисковых систем к релевантности страниц и ранжированию сайтов устаревает, всё время добавляются новые требования и ограничения
Следует помнить, что внедрение технических рекомендаций часто связано с веб- программированием, а именно с действиями веб-разработчиков. Картина мира у SEO-специалиста и веб-разработчика может различаться иногда весьма значи- тельно. Поэтому все технические рекомендации, приведённые в данной главе, будут в ко- нечном итоге преследовать две цели: � разъяснить необходимость выполнения рекомендаций с точки зрения поис- ковых систем; � объяснить, в каком формате выдавать рекомендации веб-программистам и раз- работчикам для скорейшего их выполнения. Теперь рассмотрим технические факторы по мере уменьшения их значимости
URL (uniform resource locator — «универсальный адрес ресурса») — это адрес веб- страницы, основное средство поисковиков, чтобы искать и выкачивать страницы. Обычно русскоязычные веб-мастера и веб-разработчики произносят английское название адреса как «урл», это довольно устоявшийся термин.
ЧПУ (человекопонятный урл) — это адрес страницы (URL), кратко отобража- ющий её содержание, лаконичный и удобочитаемый для русскоязычного поль- зователя
Для корректной индексации сайта поисковыми системами очень важно, чтобы на сайте использовались именно такие адреса страниц. Они должны также отражать структуру сайта. Уровни вложенности в адресе страницы должны отражать вло- женность страниц относительно корня сайта. Возьмём в качестве примера мебельный сайт. Пусть на нём есть каталог товаров, в котором одним из разделов является страница «Угловые диваны». Удобочитае- мый адрес раздела, который можно признать отвечающим стандартам ЧПУ, будет выглядеть так: domain.ru/catalog/uglovye-divany/
Ранее рекомендовалось, чтобы адреса конечных страниц, например карточек това- ров, формировались с html или php на конце (например, domain.ru/catalog/uglovye- divany/amsterdam.html), в то время как страницы категорий должны открываться со слешем (/) на конце (например, domain.ru/catalog/uglovye-divany/). Сейчас поисковые системы могут без труда различить страницу категории и кар- точки товара. Поэтому в добавлении типов файлов к конечным страницам нет необходимости. Дубли страниц
-
дубль страницы в терминологии SEO — это точная копия страницы, доступная одновременно по нескольким адресам.
-
При смене адресации или при создании новых страниц дубли могут появляться автоматически.
уществует два основных метода устранения зеркал. � Настройка постраничного редиректа 301 с зеркала на продвигаемый сайт. В данном случае настройки сервера корректируются таким образом, чтобы при запросе любой страницы дубля происходил редирект 301 на соответствующую страницу основного домена (например, при запросе http://test.domain.ru/ — на страницу https://www.domain.ru/). Способы настройки редиректа 301 зачастую зависят от конкретной CMS и настроек хостинга, на котором размещается сайт. � Закрывание зеркала от индексации. В этом случае в корне зеркала корректи- руется содержимое файла robots.txt. В результате содержимое файла должно выглядеть следующим образом: User-Agent: * '()�%%�*+ � Подробнее о назначении и использовании файла robots.txt

Управление файлом robots.txt Как мы уже говорили, файл robots.txt содержит набор директив, позволяющих управлять индексацией сайта. Он позволяет указывать поисковым системам, какие каталоги, страницы сайта или файлы должны присутствовать в поиске, а какие — нет. Вот основные правила использования этого файла.
Это текстовый файл в простом текстовом формате. Файл должен быть сохра- нён в формате plain text в кодировке ASCII или UTF-8 и называться robots.txt.
Файл создаётся в текстовом редакторе (Блокноте) или аналогичных программах (но не в Word или других текстовых редакторах со своим специальным форматом). � Файл robots.txt размещается в корневом каталоге сайта. Чтобы контролиро- вать сканирование всех страниц сайта http://www.domain.ru/, соответствующий файл robots.txt следует разместить по адресу http://www.domain.ru/robots.txt в корне сайта. Он не должен находиться где-то в подкаталоге (например, по адресу http://www.domain.ru/pages/robots.txt). � На сайте файл robots.txt должен быть единственным. Если сайт создан с по- мощью вашей CMS, то он будет генерироваться автоматически. В файле robots.txt поисковый робот проверяет наличие записей, начинающихся с поля User-agent. Данная директива определяет робота поисковой системы, к ко- торому относится это конкретное правило индексирования сайта. В описании адресов на сайте можно использовать квантор (wildcard) «», он под- разумевает «любую последовательность символов» и используется для обозначения префикса или суффикса пути до каталога или страницы по сайту (или вообще всего пути). Внутри директивы User-agent возможно использование следующих правил. � Должна быть хотя бы одна директива. В каждом правиле должна быть по крайней мере одна директива Disallow: (Запретить) или Allow: (Разрешить). � Disallow:. Указывает на каталог или страницу в корневом домене, которые нельзя сканировать поисковым роботом, определённым выше. Если это каталог, путь к нему должен заканчиваться слешем. Поддерживается квантор «» для обозначения префикса/суффикса пути или всего пути. � Allow:. Директива указывает на каталог или страницу в корневом домене, которые нужно сканировать поисковым роботом (с User-agent, определённым выше). Используется также для того, чтобы отменить директиву Disallow: и раз- решить сканирование конкретного подкаталога или страницы в закрытом для сканирования каталоге. Если указывается каталог, путь к нему должен заканчиваться слешем. Под- держивается квантор «*» для обозначения префикса/суффикса пути или всего пути.
� Sitemap. Необязательная директива, их может быть несколько или совсем не быть. Указывает на расположение карты сайта — файла Sitemap. Можно перечислить несколько файлов Sitemap, каждый на отдельной строке. Более подробно о тре- бованиях к карте сайта Sitemap будет написано в следующем разделе. � Неизвестные директивы игнорируются. Это позволяет при необходимости писать комментарии в файле robots.txt. В зависимости от поисковых систем часть директив могут различаться. Актуаль- ные требования основных поисковых систем к файлу robots.txt можно найти по ссылкам ниже: https://yandex.ru/support/webmaster/controlling-robot/; https://support.google.com/webmasters/answer/6062596?hl=ru.
Создание и тщательная подготовка robots.txt крайне важны. При его отсутствии поисковые роботы собирают всю информацию, относящуюся к сайту. В поиске могут появиться незаполненные страницы, служебная информация или тестовая версия сайта
Часть III. Работа с основными факторами ранжирования сайта178 Создание и тщательная подготовка robots.txt крайне важны. При его отсутствии поисковые роботы собирают всю информацию, относящуюся к сайту. В поиске могут появиться незаполненные страницы, служебная информация или тестовая версия сайта (например, test.domain.ru или dev.domain.ru) (рис. 9.3). Рис. 9.3. Тестовые домены сайта в индексе поисковых систем Сейчас поисковые роботы не способны отличить тестовый домен от основного. Для них это просто два сайта с одинаковым контентом. Это обязательно сработает как негативный фактор ранжирования. Тестовую версию сайта следует закрывать от индексации с помощью таких ди- ректив:

Бывает и наоборот, когда после разработки тестовую версию выкладывают на основной домен, забыв снять запрет на индексацию. Тогда новый сайт перестаёт индексироваться и полностью выпадает из результатов поиска. Поэтому после переноса сайта с тестового домена на основной или завершения раз- работки необходимо обязательно проверить содержимое файла robots.txt. Если запрет стоит — снять его и указать актуальный набор директив. В Яндекс.Вебмастере можно загрузить актуальный скорректированный файл и про- верить, какие директивы он разрешает и запрещает для индексации поисковым роботам https://webmaster.yandex.ru/tools/robotstxt
Коды ответа сервера При запросе страницы с сайта поисковая система получает от сервера некоторый код ответа. Так, например, двухсотый код ответа, или 200 OK, указывает, что со страницей всё в порядке — её можно индексировать и представить в результатах поиска. Есть специальные коды, предназначенные для редиректов и ошибок. Их нужно правильно настроить. Некорректная обработка кодов ответа может привести к се- рьёзным проблемам с ранжированием и даже к исключению страниц из поисковой выдачи. Редиректы 301/302
Коды ответа 301 и 302, как правило, используются при смене адресации сайта и нужны, чтобы указать поисковым системам, что сайт переехал с одного адреса на другой. При обращении к конкретным URL может происходить 301- и 302-редирект на новый адрес. Но на самом сайте ссылки, при переходе по которым происходит перенаправление, должны отсутствовать. Это обусловлено тем, что ссылки с реди- ректами создают дополнительную нагрузку на поисковых роботов Работа с основными факторами ранжирования сайта Яндекс говорит об этом так: «Избыточное автоматическое перенаправление (редиректы). По возможности из- бегайте использования редиректов. Редирект может быть полезен только в том случае, если адреса страниц меняются по техническим причинам и необходимо перенаправить пользователя на новый адрес страницы. Как правильно поставить перенаправление (301-редирект) со старой страницы на новую, читайте в соот- ветствующем разделе помощи. Заметьте, что по умолчанию серверы используют 302-редирект, что не гарантирует того, что в результатах поиска будет показана цель редиректа (в отличие от 301-редиректа)»
Код 304 Цель кода 304 — сообщить клиенту (браузеру или поисковику) информацию о последних изменениях конкретной страницы. Серверу передаётся заголовок If-Modified-Since или If-None-Match, и, если изменений на странице не обнаружено, от сервера должен возвращаться заголовок 304 Not Modified
При этом страница не загружается. Настройка кода ответа 304 нужна в первую очередь для снижения нагрузки на сервер и ускорения индексации страниц. Это важная часть оптимизации, особенно для крупных сайтов с большим количеством страниц. Если же изменения вносились, то сервер вернёт заголовок 200 OK и страница за- грузится с обновлённым содержимым
Благодаря корректной настройке времени обновления страницы: � ускоряется загрузка страниц для пользователей; � снижается нагрузка на сервер; � в результатах поиска отображается дата последнего обновления содержимого страницы; � страницы при сортировке в поисковике по дате занимают более высокие по- зиции; � существенно ускоряется индексация страниц. Проверить, правильно ли настроен код 304, можно с помощью сервиса http:// last-modified.com/ru/
Настройка кода ответа 304 не является обязательной и критической, но она может значительно облегчить и ускорить индексацию сайта, особенно с большим коли- чеством страниц.
Код 404 При обращении к несуществующей странице (например, domain.ru/test) сервер должен выдавать код 404 (ответ HTTP/1.1 404 Not Found). Некорректная обработка этого запроса может привести к неправильной индексации сайта, появлению большого количества дублей и мусорных страниц в индексах поисковых систем. Желательно, чтобы страница, выдаваемая при вводе некорректного URL, была выполнена в рамках общего дизайна сайта и имела ссылки на основные разделы меню и главную страницу
Проверку корректного кода ответа можно провести с помощью одного из сервисов: � https://bertal.ru/; � https://webmaster.yandex.ru/tools/server-response/. Они должны показать, что код работает без ошибок (рис. 9.9). Современные CMS устроены таким образом, что корректно настроенная обработка ошибки 404 на одном типе страниц, например, для страницы карточек товаров, вовсе не означает, что код 404 будет корректно обрабатываться на других типах страниц. Это происходит потому, что современные сайты — это набор шаблонных страниц. Например, для интернет-магазина это такие типы страниц: � главная страница; � страница категории/подкатегории; � страницы товара; � информационная страница (контакты, о магазине и др.)
Для каждого типа страниц обычно создаётся свой скрипт генерации страницы. В нём обработка ошибки 404 может быть своей, специфической. Необходимо проверить корректную обработку ошибки 404 для каждого типа страниц.
HTML-карта сайта HTML-карта сайта — это страница, на которой отражена структура ресурса с воз- можностью перейти в нужный раздел или документ . Обычно её создают не для поисковых роботов, а для посетителей сайта. Она помогает сориентироваться в структуре контента на сайте. Не менее важная причина создания карты сайта — помощь поисковым системам. Карту используют для быстрой индексации сайта поисковыми роботами и создания древовидной структуры сайта, чтобы все страницы были максимум в двух кликах от главной. Это важно для быстрой индексации. Стоит добавлять в HTML-карту сайта только значимые и важные страницы, на- пример ссылки на основные разделы и подразделы сайта. В случае с интернет-магазинами не нужно добавлять в карту сайта ссылки на все товары, особенно если их много. Такая карта не сможет помочь пользователям, так как будет загружаться слишком долго и многие посетители покинут страницу, так и не дождавшись нужной информации. Кроме того, даже если они увидят карту, им будет непросто найти какую-либо информацию на странице, содержащей сотни и тысячи ссылок
XML-карта сайта XML-карта сайта (файл Sitemap) — это документ, который сообщает поисковым системам о страницах сайта, доступных для индексации. Этот файл представляет собой XML-файл, в котором перечислены URL-адреса страниц сайта в сочетании с метаданными, связанными с каждым URL-адресом (дата его последнего изме- нения, частота изменений, его приоритетность в рамках сайта), чтобы поисковые системы могли оптимизировать процесс индексации сайта. Карта сайта должна включать в себя ссылки только на значимые страницы сайта, содержащие уникальный контент. В карте сайта не должно быть: � страниц, выдающих коды ответов 30* или 404; � страниц, закрытых от индексации; � страниц-дублей; � неинформативных или пустых страниц. Кроме того, согласно правилам составления XML-карты сайта, рекомендуется следующее.
- Добавить в файл атрибут , который указывает на дату последнего изменения файла. Дата должна проставляться автоматически при любом из- менении документа. Пример:

Как создать файл Sitemap и сделать его доступным для Google
Выберите подходящий формат файла Sitemap.
Создайте файл Sitemap автоматически или вручную.
Убедитесь, что у Google есть доступ к файлу Sitemap.
Форматы файлов Sitemap
В Google поддерживается несколько форматов файлов Sitemap:
XML
RSS, mRSS и Atom 1.0
Текстовый
Во всех форматах следует использовать стандартный протокол. В настоящее время Google не учитывает в файлах Sitemap атрибут .
Для всех форматов действуют следующие ограничения: файл Sitemap может содержать не более 50 000 URL, а его размер в несжатом виде не должен превышать 50 МБ. Если объем файла или количество перечисленных в нем адресов превышают эти лимиты, разбейте его на несколько частей. Вы можете создать и отправить в Google индекс Sitemap, который содержит данные об отдельных файлах Sitemap. При необходимости можно отправить несколько файлов и/или индексов Sitemap.
Подробную документацию и более сложные примеры вы можете найти на сайте sitemaps.org.
Также предлагаем изучить примеры файлов Sitemap с указанием версий страниц на разных языках и файлов для новостей, изображений и видео.
RSS, mRSS и Atom 1.0
Если у вас есть блог с фидом RSS или Atom, можно отправить URL этого фида в качестве источника файла Sitemap. Большинство сервисов для ведения блогов позволяют создать фид, но нужно учитывать, что такие фиды предоставляют информацию только о последних URL.
Google поддерживает фиды RSS 2.0 и Atom 1.0.
Отправить в Google сведения о видеоконтенте можно также с помощью фида mRSS (media RSS).
Текст
Если в файле Sitemap есть только адреса страниц, вы можете отправить Google обычный текстовый файл с этими URL (по одному в каждой строке). Пример:
https://www.example.com/file1.html https://www.example.com/file2.html
Правила создания текстовых файлов Sitemap
Необходимо использовать кодировку UTF-8.
В файл Sitemap можно добавлять только URL.
Этому текстовому файлу можно дать любое имя, но необходимо использовать расширение .txt (например, sitemap.txt).
Файлы Sitemap с расширенным синтаксисом
Google поддерживает расширенный синтаксис файлов Sitemap для перечисленных ниже MIME-типов. С помощью дополнительных элементов можно описывать видео, изображения и другой плохо поддающийся анализу контент, чтобы они лучше индексировались.
Видео
Изображения
Google Новости
Общие рекомендации в отношении файлов Sitemap Указывайте полные URL, используя один и тот же синтаксис. Google будет сканировать в точности те URL, которые вы перечислите. Например, если адрес сайта – https://www.example.com/, не указывайте URL https://example.com/ (без www) или ./mypage.html (относительный). Файл Sitemap может быть размещен в любой части сайта, но влияет только на каталоги уровнем ниже родительского. Поэтому, чтобы файл Sitemap действовал на весь сайт, мы рекомендуем располагать его на корневом уровне. Не указывайте в добавляемых URL идентификаторы сеансов или иные идентификаторы, относящиеся к пользователям. Это может привести к избыточному сканированию страниц. Отмечайте иноязычные версии страницы атрибутом hreflang. Файлы Sitemap должны создаваться в кодировке UTF-8, а в URL необходимо применять экранирование. Разбивайте большие файлы Sitemap на файлы поменьше. Файл Sitemap может содержать до 50 000 URL и не должен занимать больше 50 МБ в несжатом виде. Вместо отдельных файлов Sitemap отправляйте в Google их индекс. Включайте в файлы Sitemap только канонические URL. Если у вас две версии страницы, укажите только ту, которая должна появляться в результатах поиска. Если у вас две версии сайта (например, с префиксом www и без него), выберите основную и разместите файл Sitemap в ней, а на страницы второго сайта добавьте атрибут rel=canonical или реализуйте на них переадресацию. Если у мобильной и обычной версии страницы разные URL, советуем указывать только одну из них. Если все же требуется включить в файл оба URL, добавьте для них аннотации, чтобы обозначить эти версии. Используйте файлы Sitemap с расширенным синтаксисом для указания дополнительных MIME-типов, например изображений, видео и новостей. Если существуют версии страницы на других языках или для других регионов, вы можете указать их с помощью атрибута hreflang в файле Sitemap или тегах HTML. Символы помимо букв латинского алфавита и цифр требуют особого обращения. Файл Sitemap обязательно должен быть в кодировке UTF-8 (обычно ее можно выбрать при сохранении). Как и в любых других XML-файлах, при вводе значений (включая URL) необходимо экранировать символы в соответствии с приведенной ниже таблицей. Файл Sitemap может содержать только символы ASCII. В нем не должно быть расширенных символов ASCII, определенных управляющих кодов и специальных символов, таких как * и {}. Если они есть в URL, то при попытке добавить файл появится сообщение об ошибке.
Кроме того, все URL (включая адрес вашего файла Sitemap) должны быть правильно экранированы и закодированы, чтобы их мог обработать веб-сервер. Обычно это выполняется автоматически, если для создания URL вы применяете какой-либо скрипт, инструмент или файл журнала, то есть не вводите адреса вручную. Если при отправке файла Sitemap вы получаете оповещение о том, что Google не удалось найти ваши URL, убедитесь, что они соответствуют стандарту RFC-3986 для URI, стандарту RFC-3987 для IRI и стандарту XML.
Пример URL, где есть символ, не относящийся к кодировке ASCII (ü), а также символ, который требует экранирования (&): Google(Yandex) не гарантирует сканирование каждого URL, указанного в файле Sitemap. Такие файлы лишь помогают Google(Yandex) определить, какие страницы вы считаете важными. Значения в тегах и игнорируются. В Google используется значение в теге , если оно всегда является гарантированно точным (например, если его точность проверяется путем сравнения с последней измененной версией страницы). Позиция того или иного URL в файле Sitemap не важна. Google сканирует URL, не учитывая их порядок в этом файле.
Как создать файл Sitemap
Создавая файл Sitemap, вы сообщаете поисковым системам, какие из ваших URL следует выбирать для показа в результатах поиска. Такие URL называются каноническими. Если вы разместили одинаковый контент по нескольким URL, выберите основной вариант страницы и включите в файл Sitemap только его.
Выбрав URL, которые следует добавить в файл Sitemap, создайте его одним из перечисленных ниже способов. Оптимальный вариант будет зависеть от архитектуры и размеров сайта.
Файл Sitemap можно сгенерировать с помощью системы управления контентом.
Если в файле несколько десятков URL или меньше, попробуйте создать его вручную.
Если ожидается, что файл Sitemap будет очень велик, создавайте его автоматически.
Как создать файл Sitemap с помощью системы управления контентом
Если вы работаете с системой управления контентом, такой как WordPress, Wix или Blogger, то возможно, что она уже сгенерировала файл Sitemap, доступный поисковым системам. Попробуйте найти сведения о том, как ваша система управления контентом создает файлы Sitemap, или о том, как подготовить такой файл, если она не сделала этого автоматически. Например, если вы работаете с Wix, введите в Google Поиске запрос "wix sitemap".
В остальных случаях вам потребуется создать файл Sitemap самостоятельно. Как создать файл Sitemap вручную
Если вы планируете добавить в файл Sitemap несколько десятков URL или меньше, его можно создать вручную. Для этого откройте текстовый редактор, такой как Блокнот (Windows) или nano (Linux, macOS), и начните вносить данные в новый файл. При этом нужно использовать синтаксис, который описан в разделе Форматы файлов Sitemap выше. Название файла может быть любым, но оно должно состоять только из символов, которые разрешены в URL.
Вручную можно создавать и крупные файлы Sitemaps, но это очень трудоемкий процесс. Как создать файл Sitemap автоматически
Если вам нужно включить в файл Sitemap множество URL, то удобнее будет создавать его автоматически. Сгенерировать файл Sitemap можно с помощью различных инструментов, но лучше всего воспользоваться для этого средствами вашего сайта. Например, вы можете извлечь URL, относящиеся к сайту, из его базы данных и экспортировать эти адреса на экран или в файл на вашем веб-сервере. При необходимости обратитесь к разработчикам или менеджеру сервера. Ознакомьтесь с нашей подборкой сторонних генераторов файлов Sitemap: вы можете создать на их основе аналогичный инструмент.
Учтите, что размер файла Sitemap не должен превышать 50 МБ. Подробнее об управлении крупными файлами Sitemap… Как сделать файл Sitemap доступным для Google
Файл Sitemap анализируется только при первом его обнаружении, а не при каждом сканировании сайта. Чтобы файл был обработан повторно, сообщите нам, что данные в нем изменились. Это делается с помощью запроса ping. Не добавляйте несколько раз одинаковые файлы Sitemap и не отправляйте запросы ping, если в файл не вносились изменения и он не новый.
Если вы обновляли страницы, включенные в такой файл, отметьте их с помощью поля . В XML-файлах других типов есть аналогичные поля (например, в Atom XML это поле ). Подробнее о том, как определить нужную дату…
Предоставить Google доступ к файлу Sitemap можно несколькими способами:
Отправьте файл Sitemap в Search Console с помощью отчета о файлах Sitemap.
Используйте Search Console API, чтобы отправить файл Sitemap алгоритмическим методом.
Выполните запрос ping. В браузере или командной строке отправьте запрос GET на приведенный ниже адрес, указав полный URL файла Sitemap и убедившись, что этот файл доступен:

Пример:

Если вы используете Atom или RSS и хотите уведомить о внесенных вами изменениях не только Google, но и другие поисковые системы, сделайте это с помощью протокола WebSub.
Файл Sitemap служит лишь подсказкой для поисковых систем. Его наличие не гарантирует, что система Google скачает этот файл или использует его для сканирования страниц на сайте.
Файлы Sitemap для изображений
Вы можете создать отдельный файл Sitemap для изображений или указать изображения в существующем. Это поможет Google найти на вашем сайте картинки, которые иначе нельзя было бы обнаружить (например, если они загружаются с помощью JavaScript). Рекомендации
Наша документация по файлам Sitemap также относится к файлам Sitemap с расширенным синтаксисом. Соблюдайте общие рекомендации в отношении файлов Sitemap.
Следуйте рекомендациям в отношении контента для Google Картинок и рекомендациям на странице Общие сведения о Google Поиске.
Вы можете добавить метаданные для изображений, например контактную информацию или сведения о лицензировании. Эти данные будут отображаться в результатах поиска.
Пример файла Sitemap
Вот как выглядит файл Sitemap с двумя элементами :
https://example.com/sample1.html (содержит два изображения);
https://example.com/sample2.html (содержит одно изображение).

Работа с поисковыми роботами
Как убедиться, что ваш сайт сканируют именно Googlebot или другие поисковые роботы Google Вы можете проверить, сканирует ли ваш сайт именно робот Googlebot (или иной поисковый робот Google). Это полезно сделать, если у вас есть подозрения, что под видом робота Googlebot к вашему сайту обращаются спамеры или другие злоумышленники.
Есть два способа проверки:
Вручную. Если нужно выполнить единичную проверку, используйте инструменты командной строки. В большинстве случаев этого достаточно для решения задачи.
Автоматически. Если нужно выполнить масштабную проверку, используйте автоматическую систему и сопоставьте IP-адрес определенного поискового робота со списком опубликованных IP-адресов робота Googlebot.
Как создать файл robots.txt
С помощью файла robots.txt вы можете указывать, какие файлы на вашем сайте будут видны поисковым роботам. Файл robots.txt находится в корневом каталоге вашего сайта. Например, на сайте www.example.com он находится по адресу www.example.com/robots.txt. Это обычный текстовый файл, который соответствует стандарту исключений для роботов и содержит одно или несколько правил. Каждое из них запрещает или разрешает тому или иному поисковому роботу доступ к определенному пути в домене или субдомене, в котором размещается файл robots.txt. Все файлы считаются доступными для сканирования, если вы не указали иное в файле robots.txt.
Ниже приведен пример простого файла robots.txt с двумя правилами.

Агенту пользователя с названием Googlebot запрещено сканировать любые URL, начинающиеся с https://example.com/nogooglebot/.
Любым другим агентам пользователя разрешено сканировать весь сайт. Это правило можно опустить, и результат будет тем же. По умолчанию агенты пользователя могут сканировать сайт целиком.
Файл Sitemap этого сайта находится по адресу https://www.example.com/sitemap.xml.
Как создать файл robots.txt
Создать файл robots.txt можно в любом текстовом редакторе, таком как Блокнот, TextEdit, vi или Emacs. Не используйте офисные приложения, поскольку зачастую они сохраняют файлы в проприетарном формате и добавляют в них лишние символы, например фигурные кавычки, которые не распознаются поисковыми роботами. Обязательно сохраните файл в кодировке UTF-8, если вам будет предложено выбрать кодировку.
Правила в отношении формата и расположения файла
Файл должен называться robots.txt.
На сайте должен быть только один такой файл.
Файл robots.txt нужно разместить в корневом каталоге сайта. Например, на сайте https://www.example.com/ он должен располагаться по адресу https://www.example.com/robots.txt. Он не должен находиться в подкаталоге (например, по адресу https://example.com/pages/robots.txt). Если вы не знаете, как получить доступ к корневому каталогу, или у вас нет соответствующих прав, обратитесь к хостинг-провайдеру. Если у вас нет доступа к корневому каталогу сайта, используйте альтернативный метод блокировки, например метатеги.
Файл robots.txt можно разместить по адресу с субдоменом (например, https://website.example.com/robots.txt) или нестандартным портом (например, https://example.com:8181/robots.txt).
Действие robots.txt распространяется только на пути в пределах протокола, хоста и порта, где он размещен. Иными словами, правило по адресу https://example.com/robots.txt действует только для файлов, относящихся к домену https://example.com/, но не к субдомену, такому как https://m.example.com/, или другим протоколам, например https://example.com/.
Файл robots.txt должен представлять собой текстовый файл в кодировке UTF-8 (которая включает коды символов ASCII). Google может проигнорировать символы, не относящиеся к UTF-8, в результате чего будут обработаны не все правила из файла robots.txt.
Как добавить правила в файл robots.txt
Правила – это инструкции для поисковых роботов, указывающие, какие разделы сайта можно сканировать. Добавляя правила в файл robots.txt, учитывайте следующее:
Файл robots.txt состоит из одной или более групп.
Каждая группа может включать несколько правил, по одному на строку. Эти правила также называются директивами. Каждая группа начинается со строки User-agent, определяющей, какому роботу адресованы правила в ней.
Группа содержит следующую информацию:
К какому агенту пользователя относятся директивы группы.
К каким каталогам или файлам у этого агента есть доступ.
К каким каталогам или файлам у этого агента нет доступа.
Поисковые роботы обрабатывают группы по порядку сверху вниз. Агент пользователя может следовать только одному, наиболее подходящему для него набору правил, который будет обработан первым.
По умолчанию агенту пользователя разрешено сканировать любые страницы и каталоги, доступ к которым не заблокирован правилом disallow.
Правила должны указываться с учетом регистра. К примеру, правило disallow: /file.asp распространяется на URL https://www.example.com/file.asp, но не на https://www.example.com/FILE.asp.
Символ # означает начало комментария.
Правила в файлах robots.txt, поддерживаемые роботами Google
user-agent: (обязательное правило, может повторяться в пределах группы). Определяет, к какому именно автоматическому клиенту (поисковому роботу) относятся правила в группе. С такой строки начинается каждая группа правил. Названия агентов пользователя Google перечислены в этом списке. Используйте знак *, чтобы заблокировать доступ всем поисковым роботам (кроме роботов AdsBot, которых нужно указывать отдельно). Примеры:

disallow: (каждое правило должно содержать не менее одной директивы disallow или allow). Указывает на каталог или страницу относительно корневого домена, которые нельзя сканировать агенту пользователя. Если правило касается страницы, должен быть указан полный путь к ней, как в адресной строке браузера. В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
allow: (каждое правило должно содержать не менее одной директивы disallow или allow). Указывает на каталог или страницу относительно корневого домена, которые разрешено сканировать агенту пользователя. Используется для того, чтобы переопределить правило disallow и разрешить сканирование подкаталога или страницы в закрытом для обработки каталоге. Если правило касается страницы, должен быть указан полный путь к ней, как в адресной строке браузера. Если правило касается каталога, строка должна заканчиваться символом /. sitemap: (необязательная директива, которая может повторяться несколько раз или не использоваться совсем). Указывает на расположение файла Sitemap, используемого на сайте. URL файла Sitemap должен быть полным. Google не перебирает варианты URL с префиксами http и https или с элементом www и без него. Из файлов Sitemap роботы Google получают информацию о том, какой контент нужно сканировать и как отличить его от материалов, которые можно или нельзя обрабатывать

Все правила, кроме sitemap, поддерживают подстановочный знак * для обозначения префикса или суффикса пути, а также всего пути.
Строки, не соответствующие ни одному из этих правил, игнорируются.
Ознакомьтесь со спецификацией Google для файлов robots.txt, где подробно описаны все правила.
Как загрузить файл robots.txt
Сохраненный на компьютере файл robots.txt необходимо загрузить на сайт и сделать доступным для поисковых роботов. Специального инструмента для этого не существует, поскольку способ загрузки зависит от вашего сайта и серверной архитектуры. Обратитесь к своему хостинг-провайдеру или попробуйте самостоятельно найти его документацию (пример запроса: "загрузка файлов infomaniak").
После загрузки файла robots.txt проверьте, доступен ли он для роботов и может ли Google обработать его. Как протестировать разметку файла robots.txt
Чтобы убедиться, что загруженный файл robots.txt общедоступен, откройте в браузере окно в режиме инкогнито (или аналогичном) и перейдите по адресу файла. Пример: https://example.com/robots.txt. Если вы видите содержимое файла robots.txt, то можно переходить к тестированию разметки.
Для этой цели Google предлагает два средства:
Инструмент проверки файла robots.txt в Search Console. Этот инструмент можно использовать только для файлов robots.txt, которые уже доступны на вашем сайте.
Если вы разработчик, мы рекомендуем воспользоваться библиотекой с открытым исходным кодом, которая также применяется в Google Поиске. С помощью этого инструмента файлы robots.txt можно локально тестировать прямо на компьютере.
Как отправить файл robots.txt в Google Когда вы загрузите и протестируете файл robots.txt, поисковые роботы Google автоматически найдут его и начнут применять. С вашей стороны никаких действий не требуется. Если вы внесли в файл robots.txt изменения и хотите как можно скорее обновить кешированную копию, следуйте инструкциям
Битые ссылки Наличие на сайте так называемых битых ссылок (ссылок, ведущих на несуществу- ющие страницы или документы) негативно воспринимается как пользователями, так и поисковыми системами. Как правило, после перехода по несуществующей ссылке пользователи просто покидают сайт. В случае с поисковыми системами ситуация аналогична редиректам на сайте: при переходе по ссылкам на несуществующие страницы поисковые системы затрачи- вают дополнительные ресурсы, которые могли бы быть направлены на индексацию других полезных страниц на сайте. Чаще всего битые ссылки на сайте появляются из-за обновления контента (на- пример, на сайте интернет-магазина была удалена страница товара, в то время как ссылка на эту страницу осталась, например в разделе «Акции» или «Новости»).
Метатеги для индексации сайта
С помощью метатегов можно также управлять индексацией сайта, закрывая какие- либо фрагменты текста, ссылки или страницы. Метатег robots Данный тег аналогичен по своему назначению файлу robots.txt (но относится к конкретной странице, а не ко всему сайту) и позволяет указывать поисковым роботам, какие страницы индексировать, а какие — нет. Приведём описание функционала этого тега, которое даёт Яндекс

Атрибут rel="nofollow"
спользование атрибута rel="nofollow" позволяет запретить поисковым роботам переходить по определённым ссылкам. Атрибут в первую очередь используют для того, чтобы указать поисковому роботу приоритеты при сканировании сайта. Он за- прещает переходить на малополезные страницы и экономит время индексации
Код с атрибутом будет выглядеть так:

Метатег Сразу стоит отметить, что метатег воспринимается только поис- ковой системой Яндекс, Google данный тег не поддерживает. Тег предназначен для запрета от индексации элементов на странице. Это могут быть как части кода (например, код всплывающего (pop-up) окна с формой обратной связи), так и дубли контента, например описания, дублирующиеся на страницах сайта


Канонические ссылки
При наличии на сайте страниц со схожим контентом можно указать поисковому роботу на то, какие страницы должны присутствовать в поиске, а какие необходи- мо исключить. Для этого на страницах, которые необходимо исключить, в разделе
нужно указать адрес предпочтительной страницы. Например, если для страницы http://www.domain.ru/catalog/page-2 предпочтительным адресом является http://www.domain.ru/catalog, то в коде страницы http://www.domain.ru/ catalog/page-2 необходимо отразить это следующим образом:
Внутренние ссылки сайта (перелинковка) Навигационная строка (путь к странице) Чтобы упростить навигацию на сложных сайтах, в Интернете есть распространён- ный приём: в верхней части страницы располагается навигационная строка 1 , со- держащая путь к странице по структуре сайта со ссылками на все промежуточные страницы. Например, для страницы http://www.domain.ru/category/page этот элемент будет вы- глядеть следующим образом: Главная / Категория/ Страница Для корректной работы навигационной строки:
� она должна быть расположена на всех страницах сайта, кроме главной (корневой каталог); � должна находиться вверху страницы, непосредственно над или под заголов- ком H1; � не должна дублироваться на странице; � ссылками должны являться все пункты строки, за исключением текущего (по- следнего). Навигационные строки помогают и пользователям, и поисковым роботам. Пользователю за счёт них становится понятна структура сайта, проще ориенти- роваться на нём. Особенно это важно в том случае, если пользователь попадает на внутреннюю страницу сайта напрямую из поисковика и потом хочет «подняться» по структуре выше. При этом страницы сайта, которые находятся выше в иерархической структуре, обеспечиваются ссылочным весом с помощью внутренних ссылок с других стра- ниц сайта. Это позволяет обеспечить более эффективное продвижение страниц, релевантных ключевым запросам
Оптимизация HTML-кода страниц
Структурные заголовки
Если на странице размещён текст, его нужно структурировать. При этом исполь- зуют теги заголовков
Наиболее важным является заголовок он должен указывать на смысловое содержание страницы. На странице допускается использование только одного заголовка , не содержащего атрибуты, вложенные стили и теги Заголовки , как правило, применяются в текстах для обозначения ключевых разделов и привлечения к ним внимания. Заголовки не должны исполь- зоваться в элементах навигации и сквозных (расположенных на каждой странице) блоках на сайте.
Вёрстка
Простой код и отсутствие ошибок в нём позволят поисковым роботам быстрее и без лишних препятствий индексировать сайт. Поэтому очень важно выявить и устранить все существующие ошибки. Наиболее распространённый тип ошибок — незакрытые или лишние теги. Проверить корректность оформления вёрстки можно с помощью сервиса
https://find-xss.net/findtags/
Мобильная версия В 2018 году мобильная версия сайта, или адаптивная вёрстка (вёрстка сайта, ко- торая трансформируется под мобильное устройство и ПК), стала необходимостью. Ориентация на мобильных пользователей прослеживается как у владельцев сайтов, так и у поисковых систем. В топ-10 поисковых систем, особенно по высокочастот- ным и высококонкурентным запросам, уже сложно найти сайты, не адаптированные под мобильные устройства. В 2016 году Яндекс запустил алгоритм «Владивосток», в результате внедрения которого сайты, адаптированные под мобильные устройства, получают приоритет при ранжировании в мобильной выдаче. Аналогичный алгоритм Mobile Friendly Update был запущен Google еще в 2015 году. В июле 2018 года Google изменил подход в ранжировании сайтов, запустив новый алгоритм Mobile-First Indexing. Он позволяет хранить в поисковом индексе как мобильную, так и десктопную версию сайта, а значит, учитывать параметры мо- бильной версии для мобильной версии поиска. До этого в мобильной версии поиска использовались метрики десктопной версии сайта. Для проверки сайта на адаптированность к мобильным устройствам существуют специальные сервисы Яндекса и Google
Проверка на «мобильность» в сервисе Google Сейчас существует два способа адаптации сайта к мобильным устройствам — это адаптивная вёрстка и использование мобильной версии сайта. Рассмотрим плюсы и минусы каждого метода. Адаптивная вёрстка предусматривает разработку и поддержку одного универсаль- ного сайта, на одном домене. Плюс этого решения — удобство и простота внесения изменений. Минусы — сложность реализации и дороговизна. Альтернатива этому — мобильная версия сайта. В этом случае версия сайта, адапти- рованная под мобильные устройства, выносится на отдельный домен или поддомен. Этот вариант проще в разработке, но имеет существенный минус — необходимо ве- сти в дальнейшем два сайта одновременно (как основной, так и мобильную версию). Кроме того, для мобильной версии сайта нужны отдельные усилия по её поисковой оптимизации
Требуется отдельный robots.txt, составленный исключительно для неё.
� XML-карта сайта в мобильной версии должна содержать только страницы мо- бильной версии сайта.
� Нужно позаботиться о том, чтобы поисковые системы не сочли контент ду- блированным. Чтобы указать поисковым роботам на мобильную версию, на обычной странице (например, на http://www.example.com/page-1) необходимо добавить следующий код:

На странице для мобильных устройств (http://m.example.com/page-1) нужно до- бавить атрибуты:

Типовые ошибки в структуре сайта
Здесь стоит разобрать основные типы ошибок, допускаемые пользователями.
 Размытый фокус. Страница оптимизирована одновременно под несколько
интентов (потребностей пользователей), причём часто несовместимых для кор-
ректного продвижения на одной странице. Например: раздел «Кресла и стулья»
(http://divani-i-krovati.ru/category/kresla-i-stulja/).
Пользователи редко вводят в поиске именно такое словосочетание, как можно
убедиться по данным wordstat.yandex.ru (запрос в wordstat указан с использова-
нием дополнительных операторов, с помощью которых задана точная форма
запроса с неизменным порядком слов)
Размытый фокус. Страница оптимизирована одновременно под несколько
интентов (потребностей пользователей), причём часто несовместимых для кор-
ректного продвижения на одной странице. Например: раздел «Кресла и стулья»
(http://divani-i-krovati.ru/category/kresla-i-stulja/).
Пользователи редко вводят в поиске именно такое словосочетание, как можно
убедиться по данным wordstat.yandex.ru (запрос в wordstat указан с использова-
нием дополнительных операторов, с помощью которых задана точная форма
запроса с неизменным порядком слов)
Гораздо эффективнее было бы создать два отдельных раздела — «Кресла» и «Стулья».
Выводы
Техническая часть оптимизации крайне важна для дальнейшего продвижения, она — основа всей работы. Необходимо позаботиться о том, чтобы на сайте не было ошибок вёрстки, чтобы все теги и метатеги были оформлены правильно и выпол- нялись другие технические требования поисковых систем.
К работам с семантическим ядром, которые можно автоматизировать, относят: � сбор запросов из сервисов Вордстат, Яндекс.Вебмастер и Яндекс.Метрика, Search Console, поисковых подсказок и других источников;
� чистку запросов — определение интентов, геозависимости и «коммерческости», удаление нецелевых запросов и неявных дублей;
� работу с частотами запросов — определение частот (общих, уточнённых, точ- ных) для необходимых регионов, определение сезонности в тематике;
� кластеризацию собранных запросов.
Сервисов и программ, позволяющих работать с семантикой сайта, очень много: � KeyCollector — программа, обладающая обширным набором функций для ра- боты с семантикой. Среди основных возможностей программы: сбор ключевых слов из большого числа источников (Вордстат, Google AdWords, поисковые подсказки, интеграция с другими сервисами и базами ключевых слов), сбор статистики из различных сервисов (Яндекс.Директ, Roostat, MOAB, SpyWords, SERrush, Serpstat, SeoPult и др.), работа с выдачей поисковых систем (опреде- ление позиций, сохранение и экспорт истории позиций, анализ релевантных страниц и т. д.), большой набор инструментов для работы с ключевыми словами (поиск явных и неявных дублей, анализ групп поисковых фраз, поиск фраз со стоп-словами и многое другое).
Каждая из функций имеет множество настроек, которые позволяют собирать разнообразные данные. Программа также имеет интеграцию с сервисами «анти- капчи» (позволяющими автоматически проходить проверку поисковиков на «роботность» при запросе), есть возможность работы с прокси-серверами, раз- личными аккаунтами Яндекса и Google, с платными API различных сервисов.
Rush Analytics, JustMagic, Serpstat, Пиксель Тулс — эти инструменты делают сбор семантического ядра, определение частот запросов, распознавание интен- тов, определение степени «коммерческости», выполняют кластеризацию «по топу», детальный анализ запросов.
MOAB Tools, базы Пастухова, Букварикс — базы ключевых слов с различными возможностями по выборкам.
Абсолютно бесплатным является Букварикс — можно пользоваться онлайн-версией, либо скачать всю базу к себе локально — она содержит более 2 миллиардов ключевых слов.
Сбор позиций и отчётность Большинство сервисов анализа позиций позволяет снимать позиции сайта по запро- сам в поисковых системах с учётом региона поиска и типа устройства, определять видимость сайта и сезонность тематики, некоторые могут даже хранить историю страниц результатов поиска по запросам (SERP — Search Engine Results Page). Некоторые сервисы позволяют генерировать готовые отчёты для ваших сайтов. При этом отчёты могут быть выполнены сразу в фирменном стиле вашей компа- нии — для этого нужно создать свой шаблон. Для генерации таких отчётов необхо- димо иметь доступы к сервисам Яндекс.Метрика и Google Analytics. Конечно, следует помнить, что отчёты будут содержать лишь техническую ин- формацию по параметрам сайта и запросов — они не скажут, что вам сделать для лучшего ранжирования, какие есть ошибки продвижения и т. д. К сервисам для решения таких задач можно отнести SeoRate, MegaIndex, Top- Inspector.ru, Топвизор, SE Ranking, SEOlib, SEO-reports, Reportkey и многие другие.
Поиск и анализ конкурентов Главная задача по анализу конкурентов, которую можно автоматизировать с по- мощью внешних сервисов, — выявление конкурентов в поиске. Такой функционал предоставляют многие сервисы, работающие с семантическим ядром и сбором позиций. Ещё одна задача — первичный анализ найденных конкурентов по количественным параметрам: видимость, возраст домена, число страниц в индексе Яндекса и Google, объём ссылочной массы, позиции по важным запросам, приблизительное семанти- ческое ядро, анализ посещаемости сайтов-конкурентов и т. д. Сервисы не расскажут о сильных и слабых сторонах конкурента, но дадут первичное представление о том, с кем вам придется бороться за зону видимости в поиске. К таким сервисам относятся: � SeoRate, MegaIndex, Букварикс — выявление конкурентов по выдаче и опре- деление базовых параметров продвижения;
� Serpstat, SEMrush, SpyWords, AdVodka, АДВСЁ — анализ семантических ядер конкурентов;
� SimilarWeb, PR-CY — общий анализ, базовая информация о посещаемости;
� Ahrefs, Linkpad, MegaIndex, Majestic SEO — анализ внешних ссылок.
Все эти сервисы можно использовать также и для анализа своих собственных сайтов.
Технический аудит Это задача поисковой оптимизации с самым обширным и разнообразным списком возможных подзадач, которые можно автоматизировать: � проверка доступности сайта и кодов ответа различных страниц;
� поиск 3XX-редиректов;
� поиск битых ссылок;
� проверка задания корректных директив ;
� поиск страниц-дублей;
� проверка наличия и дублирования полей h1, title, description, keywords;
� генерация карты сайта sitemap.xml;
� анализ инструкций для поисковиков в файле robots.txt;
� анализ поведения сайта с отключёнными Java-скриптами (JS);
� анализ полноты индексации сайта — сравнение индекса сайта в поисковых системах с набором страниц сайта;
� отслеживание изменений на важных страницах;
� анализ вёрстки (поиск незакрытых тегов, способных помешать корректной индексации сайта)
Инструментов для автоматизации выполнения этих задач тоже хватает. � Screaming Frog SEO Spider позволяет сканировать сайт и получить полную информацию о техническом состоянии сайта: • полный список страниц и ресурсов сайта, коды ответов (что необходимо при поиске редиректов и битых ссылок); • полная внутренняя перелинковка и исходящие ссылки на другие сайты; • анализ директив, метатегов и заголовков сайта (в том числе поиск дублей и страниц, у которых они отсутствуют) и многое другое. Это мощный инструмент, позволяющий анализировать сайт под разными зна- чениями User-Agent, в различных режимах («паук», «список страниц»), с раз- личными настройками парсинга (скорость и глубина обхода, число потоков, проверка канонических и nofollow-страниц, базовый каталог, можно ли выходить за пределы базового каталога), с поиском страниц с содержанием определённого кода и многими другими функциями. Среди бесплатных аналогов, хоть и не с таким богатым функционалом, можно отметить программу Majento SiteAnalyzer. � Яндекс.Вебмастер. Среди средств автоматизации можно выделить получение в виде уведомлений информации об изменениях на важных страницах сайта (заголовки, метатеги, коды ответов и т. д.), индексировании сайта Яндексом, а также о получении санкций или о появлении каких-либо проблем, способных помешать лучшему ранжированию (об этом будет рассказано ниже). Также позволяет массово проверить правила robots.txt для различных страниц, отправить их на новый обход сканирующим роботом и найти ошибки в карте сайта sitemap.xml. Яндекс.Вебмастер используют все SEO-специалисты — по- мимо возможностей для автоматизации процессов, он даёт много важной ин- формации о состоянии сайта в поиске и предоставляет различные инструменты для анализа сайта в ручном режиме. � SEOSan — инструмент автоматизации от Mail.Ru, также позволяющий отсле- живать изменения важных страниц. � Ping-Admin.ru, Яндекс.Метрика, Monitis, Host-tracker, UptimeInspector — инструменты, производящие автоматический мониторинг работоспособности вашего веб-сервера. � ComparseR — программа для проверки и изучения полноты индексации сайта. С её помощью можно автоматизировать сопоставление индекса сайта в Яндексе и Google. � XML-Sitemaps.com, mysitemapgenerator, Screaming Frog, Majento SiteZnalyzer — разовая генерация XML-карты сайта. Большинство сервисов дают возможность бесплатно собрать карту для ограниченного числа страниц — до 500 или 1000. Для сложных проектов рекомендуется настраивать генерацию XML-карты авто- матически средствами вашей системы управления сайтом (CMS) с ежедневным обновлением.
W3C Validator, FXN — поиск проблем в вёрстке, способных помешать корректному восприятию сайта поисковыми системами и негативно сказаться на ранжировании. � Пиксель Тулс — поиск поддоменов и зеркал для домена. Это базовые инструменты, которые вы можете использовать для сбора данных при техническом аудите сайта и отслеживании важных изменений. Для более сложных задач существуют более узкоспециализированные инструменты, но такие работы, как правило, нельзя полностью автоматизировать.
Контент
Здесь мы можем выделить такие подзадачи: � проверка уникальности контента; � составление технических заданий на тексты; � анализ качества текстов, метатегов и заголовков; � анализ микроразметки и микроформатов; � создание микроразметки сайта. Для выполнения этих задач есть разнообразные инструменты. � Content-watch, Text.ru — массовая проверка текстов или страниц сайта на уникальность. � Rush Analytics, JustMagic, Istio, Пиксель Тулс, MegaIndex — текстовые ана- лизаторы, автоматизирующие семантический анализ текстов и составление ТЗ на их написание. Также помогают в определении LSI-фраз (latent semantics indexing, поиск скрытой семантики — по существу, поиск нечётких синонимов). Для последней функции есть отдельный сервис — LSI Graph. � «Тургенев» (https://turgenev.ashmanov.com) — анализ качества текста, пере- оптимизации, рисков попадания под санкции алгоритма «Баден-Баден» и др. � Главред (https://glvrd.ru) — анализ стилистического качества текста. � Пиксель Тулс (Pixel Tools) — массовая проверка текстов, метатегов и заголов- ков страниц сайта. � Проверка структурированных данных от Google и валидатор микроразметки в Яндекс.Вебмастере позволяют проверить корректность внедрения микро- разметки на сайте. Отметим, что инструмент от Google поддерживает больше форматов, а также у него нет ограничения на размер анализируемого документа, как в валидаторе микроразметки. � Schema Markup Generator позволяет автоматизировать процесс создания ми- кроразметки в формате JSON-LD.
Ссылочная масса
Мы уже говорили об анализаторах ссылочной массы, рассказывая об анализе конку- рентов, — это сервисы Ahrefs, Linkpad, MegaIndex, Majestic SEO и др. Они позволяют получить информацию о ссылающихся доменах и конкретных страницах, типах
ссылок (follow/nofollow, прямая/редирект, изображение/текст), анкорах ссылок (безанкорные, брендовые, продвигаемые слова), дают доступ к истории развития ссылочной массы сайта, а также могут определить, является ли ссылка покупной или естественной. Правильное использование анализаторов ссылок важно при выстраивании стра- тегии наращивания ссылочной массы сайта. Для автоматизации «работ» по наращиванию ссылочной массы существует множе- ство различных бирж арендных ссылок. Слово «работ» взято в кавычки не случай- но — бездумная автоматическая закупка ссылок в этих сервисах может навредить и привести к наложению таких санкций, как алгоритмы Яндекс «Минусинск» и «Пингвин» от Гугла. Качество площадок, размещающихся на подобных биржах, оставляет желать луч- шего — если повезёт, то один из тысячи ссылочных доноров окажется неплохим и пригодным для размещения ссылок. Но это не значит, что всю тысячу вам придётся просмотреть вручную — например, у биржи Sape существует дополнение для браузеров Веб-мастер SAPE (известное также, как плагин wink), позволяющее проанализировать доноров в автоматиче- ском режиме по множеству параметров: возраст домена, количество страниц в ин- дексе Яндекс и Google, наличие страницы в индексе Яндекс и Google, количество внутренних и внешних ссылок на странице, количество внешних ссылок на сайт- донор, количество уже размещённых ссылок на странице-доноре в рамках биржи Sape, тематика сайта, наличие на странице определённых стоп-слов, расположение блока со ссылками и т. д. Параметров, на которые можно проверить доноров автоматически, достаточно много, но после этого всё равно необходимо проанализировать каждый сайт-донор вручную. Помимо арендных, существуют также биржи «вечных ссылок». Но здесь средств для автоматизации нет совсем — необходимо проверять каждого донора само- стоятельно, автоматическое размещение приведёт всё к тем же печальным по- следствиям. Можно здесь же выделить и различные крауд-сервисы, получившие большое распространение за последние три года. Как правило, вы составляете для испол- нителей ТЗ, по которому они размещают ссылки, и проверить их можно лишь уже по факту размещения. Это получается не столько автоматизация, сколько делегирование работ сервису, по окончании которых необходим тщательный руч- ной анализ
Определение проблем и санкций со стороны поисковых систем
Главные инструменты для проверки на санкции — это сервисы самих поисковых машин: Яндекс.Вебмастер и Google Webmaster Tools. Помимо указания на наложенные санкции (хотя и не все), они проинформируют и о появлении дру- гих проблем, влияющих на ранжирование сайта (отсутствие или дублирование
метатегов, отсутствие карточек организации, неадаптированность сайта для мо- бильных устройств, критические изменения во времени ответа сервера и т. д.). В определении санкций, о которых не расскажут сервисы поисковых систем, по- могут следующие сервисы. � Диагностика санкций от SEOlib — определение различных санкций. � SEO friendly — определение пост-фильтров (переспам, переоптимизация, «но- вый» фильтр). � Пиксель Тулс — определение текстовых фильтров и массовая проверка на непот-фильтр. � Тургенев — диагностика угрозы фильтра Яндекса «Баден-Баден». � Penguin Tool —определение наличия фильтров со стороны Google
О сервисе Яндекс Вебмастер
Яндекс Вебмастер помогает понимать, насколько легко ваш сайт находят пользователи. Сервис предлагает инструменты для отслеживания и анализа индексирования страниц сайта, его позиций в поиске и технического состояния. Если ваш сайт новый и еще не присутствует в поиске Яндекса, сообщите о нем с помощью Яндекс Вебмастера.
Как добавить сайт в поиск
Шаг 1. Авторизуйтесь
Войдите в Вебмастер с Яндекс ID или зарегистрируйтесь. Шаг 2. Добавьте сайт в Вебмастер Примечание. В Вебмастер можно добавить только сайт с собственным доменом.
Перейдите в Вебмастер.
Нажмите кнопку Добавить сайт.
В поле укажите адрес сайта, по которому он будет участвовать в поиске:
по протоколу HTTP или HTTPS;
с префиксом www или без него.
Например, https://www.example.com. Кириллический адрес будет автоматически перекодирован в Punycode. В этом случае кодировка URL страницы должна соответствовать кодировке самой страницы.
Нажмите кнопку Добавить. После этого сайт отобразится на странице Мои сайты.
Шаг 3. Подтвердите права на сайт
На странице Права доступа выберите один из способов подтверждения. Чтобы подтвердить права, внесите изменения на сайт.
Если вы добавили в Вебмастер сайт и его поддомены, используйте упрощенное подтверждение прав.
После подтверждения прав на управление сайтом вы можете передать права другим пользователям Вебмастера. Пользователь, которому вы делегируете права, сможет использовать все возможности сервиса. Делегировать свои права другому пользователю он при этом не сможет Примечание. Добавление сайта в Вебмастер не гарантирует, что сайт появится в результатах поиска.
Как добавить сайт в поиск
Страницы сайта могут появиться в результатах поиска, когда роботы Яндекса посетят сайт. Чтобы роботы обошли и загрузили страницы:
Шаг 1. Сделайте страницы сайта видимыми для робота
Чтобы робот Яндекса узнавал об изменениях на сайте, можно использовать несколько способов:

Шаг 2. Скройте непубличный контент

После того, как робот обойдет сайт, страницы смогут появиться в поиске в течение двух недель.
Кроме того, роботы могут узнавать о сайте, переходя по ссылкам с других ресурсов. Это может занять время и не гарантирует, что робот обойдет все страницы, которые вы бы хотели показать в результатах поиска.
Чтобы следить за индексированием и позициями сайта в поисковой выдаче, добавьте сайт в Яндекс Вебмастер. Также в Вебмастере вы можете посмотреть отображение сайта в поиске и как вы можете улучшить его — на странице Представление в поиске.
Почему страницы долго не появляются в поиске
Убедитесь, что:
страницы доступны для робота (используйте инструмент Проверка ответа сервера);
информация о страницах есть в файле Sitemap;
на страницы ведут доступные ссылки с ранее проиндексированных страниц сайта;
директивы Disallow, noindex, а также HTML-элемент noindex закрывают от индексирования только служебные и дублирующие страницы.
Проверить, что знает робот Яндекса о странице, можно с помощью инструмента Проверить URL. Чтобы сообщить роботу о появлении или обновлении нескольких страниц, отправьте их на переобход.

Анализ robots.txt

Анализ файлов Sitemap

Проверка ответа сервера

Проверка страницы

Удалить URL
Воспользуйтесь формой для удаления из поиска страницы, которая запрещена к индексации или больше не существует.

Валидатор XML-фидов

Валидатор микроразметки
Валидатор микроразметки позволяет проверить семантическую разметку, внедренную на вашем сайте, и убедиться в том, что роботы поисковых систем смогут извлечь структурированные данные.
В данный момент в валидаторе можно проверить все популярные форматы микроразметки: микроданные (microdata), schema.org, микроформаты, OpenGraph, RDFa. Однако специальные сниппеты и использование размеченных данных в сервисах предусмотрено не для всех форматов. Подробнее о том, какие структурированные данные использует Яндекс, вы можете прочитать в разделах Справки.
Подробнее о валидаторе читайте в специальном разделе Справки.











Как настроить Аналитику для сайта или приложения
Как создать аккаунт Google Аналитики
Сначала создайте аккаунт Google Аналитики, если у вас его ещё нет. Кроме того, вы можете создать другой аккаунт, если новый сайт или приложение принадлежит другой компании. Если вы не хотите создавать отдельный аккаунт для этого сайта и/или приложения, перейдите к созданию ресурса.
На странице Администратор в столбце Аккаунт нажмите Создать аккаунт.
Укажите название аккаунта. Задайте настройки доступа к данным, чтобы указать, какие именно данные вы будете предоставлять Google.
Нажмите Далее, чтобы добавить в аккаунт первый ресурс.
Как создать ресурс Google Аналитики 4.
Чтобы добавлять ресурсы в аккаунт Google Аналитики, у вас должна быть роль редактора. Если аккаунт создали вы, то роль редактора предоставляется вам автоматически. В аккаунт Google Аналитики можно добавить до 100 ресурсов (любую комбинацию ресурсов Universal Analytics и Google Аналитики 4). Если этого количества вам недостаточно, обратитесь к представителю службы поддержки.
Чтобы создать ресурс, выполните следующие действия:
Если вы создали аккаунт согласно инструкциям из раздела выше, перейдите к шагу 2. В противном случае, сделайте следующее:
На странице Администратор в столбце Аккаунт проверьте, выбран ли нужный аккаунт. В столбце Ресурс нажмите Создать ресурс.
 Укажите название ресурса, например "сайт компании "Мой бизнес", и выберите часовой пояс отчетов и валюту. Если посетитель зайдет на ваш сайт во вторник (в своем часовом поясе), но в вашем часовом поясе ещё будет понедельник, посещение зарегистрируется как совершенное в понедельник.
Укажите название ресурса, например "сайт компании "Мой бизнес", и выберите часовой пояс отчетов и валюту. Если посетитель зайдет на ваш сайт во вторник (в своем часовом поясе), но в вашем часовом поясе ещё будет понедельник, посещение зарегистрируется как совершенное в понедельник.
Google Аналитика автоматически включает и отключает летнее время, если оно используется в выбранном часовом поясе. Если вы не хотите использовать эту функцию, установите среднее время по Гринвичу.
Изменение часового пояса повлияет только на те данные, которые будут получены в дальнейшем. Если вы измените часовой пояс для существующего ресурса, то можете заметить плато или колебания показателей. Пока серверы Аналитики не обработают это изменение, данные в отчетах некоторое время могут приводиться по старому часовому поясу.
Рекомендуем менять часовой пояс для ресурса не чаще одного раза в день, чтобы Google Аналитика могла обработать это изменение.
Нажмите Далее. Выберите сферу деятельности и размер компании. Нажмите Создать и примите Условия использования Google Аналитики и Поправку в отношении обработки данных.
Как добавить поток данных
Если вы добавляете поток данных после создания ресурса в соответствии с приведенными выше инструкциями, перейдите к шагу 2. В противном случае сделайте следующее:
На странице Администратор в столбце Аккаунт проверьте, выбран ли нужный аккаунт. Затем в столбце Ресурс проверьте, выбран ли нужный ресурс.
В столбце Ресурс нажмите Потоки данных, затем Добавить поток.
Выберите нужный вариант: Приложение для iOS, Приложение для Android или web
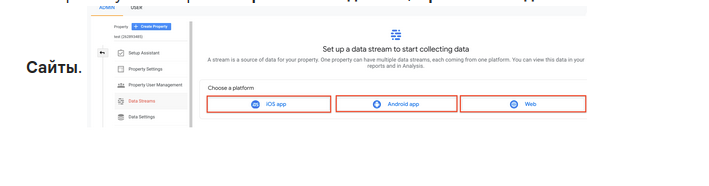
Укажите URL основного сайта, например "example.com", и название потока, например "МойРесурс (веб-поток)".
Вы можете включить или отключить улучшенную статистику. Эта функция автоматически собирает информацию о просмотрах страниц и других событиях. После создания потока данных вы сможете по отдельности отключить те события улучшенной статистики, которые вас не интересуют. Поэтому на данном этапе мы рекомендуем включить улучшенную статистику.
Нажмите Создать поток.
Google Сайты, HubSpot, Wix, WooCommerce и WordPress.com
Google Сайты, HubSpot, Wix, WooCommerce и WordPress.com
Если вы используете Google Сайты, HubSpot, Wix, WooCommerce или Wordpress.com, следуйте приведенным ниже инструкциям, чтобы найти свой идентификатор ресурса, начинающийся с "G-", и скопировать его в поле Google Аналитики в настройках системы управления контентом.
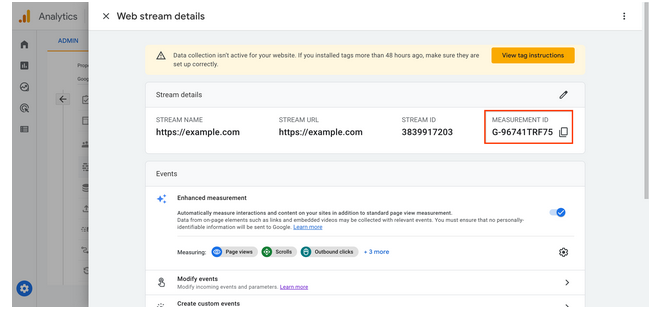
Как найти идентификатор, начинающийся с "G-"
В аккаунте Google Аналитики перейдите на вкладку Администратор.
Убедитесь, что выбран нужный аккаунт и ресурс
В столбце Ресурс нажмите Потоки данных.
Выберите поток данных. Идентификатор вида "G-" находится в правом верхнем углу.
Скопируйте этот идентификатор в нужное поле в настройках вашей системы управления контентом.
Другие конструкторы сайтов
Если вы используете любую другую систему управления контентом или конструктор сайтов, в которых нет поля для идентификатора "G-", вам будет нужно вставить тег Google на свой сайт с помощью функции добавления собственного HTML-кода системы управления контентом. В аккаунте Google Аналитики перейдите на вкладку Администратор. Убедитесь, что выбран нужный аккаунт и ресурс
Убедитесь, что выбран нужный аккаунт и ресурс.
В столбце Ресурс нажмите Потоки данных > Веб.
Выберите поток данных.
В разделе Тег Google нажмите Просмотр инструкций тега.
На странице Инструкции по установке выберите Установить вручную.
На экране вы увидите фрагмент JavaScript для тега Google вашего аккаунта. Ваш тег Google – это целый раздел кода, который начинается с

Вставьте на свой сайт тег Google с помощью функции добавления пользовательского кода в системе управления контентом (CMS), с которой вы работаете. Ниже приведены ссылки на инструкции для разных систем управления контентом.
Как добавить тег Google gtag.js прямо в код веб-страницы
Для этого вам нужен доступ к HTML-коду веб-страниц. Попросите своего веб-разработчика выполнить эти шаги, если вы не можете сделать это самостоятельно.
В аккаунте Google Аналитики перейдите на вкладку Администратор.
Убедитесь, что выбран нужный аккаунт и ресурс
Убедитесь, что выбран нужный аккаунт и ресурс.
В столбце Ресурс нажмите Потоки данных > Веб.
Выберите поток данных.
В разделе Тег Google нажмите Просмотр инструкций тега.
На странице Инструкции по установке выберите Установить вручную.
На экране вы увидите фрагмент JavaScript для тега Google вашего аккаунта. Ваш тег Google – это целый раздел кода, который начинается с

Вставьте тег Google сразу после тега на каждой странице своего сайта.
Сбор данных начнется в течение 30 минут. Откройте отчет в реальном времени, чтобы проверить, поступают ли данные.
Как найти идентификатор, начинающийся с "G-" (для любой платформы, которая принимает его)
Для использования Google Аналитики в сервисе или на платформе, которая принимает идентификатор, начинающийся с "G-", следуйте инструкциям ниже, чтобы найти его. Затем введите его в поле, предоставленное сервисом или платформой.
Как найти идентификатор, начинающийся с "G-"
В аккаунте Google Аналитики перейдите на вкладку Администратор. Убедитесь, что выбран нужный аккаунт и ресурс
В столбце Ресурс нажмите Потоки данных. Выберите поток данных. Идентификатор вида "G-" находится в правом верхнем углу.


Установка кода счётчика на сайт
Установка счётчика

Счётчик создан — теперь его код следует добавить на все страницы сайта. Код находится в настройках: нажмите на кнопку-шестерёнку.

Выберите вкладку «Счётчик» и промотайте в конец страницы.


Где размещать код
Если ваш сайт работает на CMS-системе, код счётчика нужно вставить в файл, отвечающий за генерацию заголовка (header) всех страниц сайта. В этом случае код также размещается после открывающего тега или .
Для самых популярных CMS существуют официальные плагины Метрики, которые позволяют установить код счётчика автоматически: как правило, достаточно установить плагин и пройти авторизацию.
Если сайт небольшой и все его страницы — отдельные файлы, написанные вручную, код необходимо разместить в пределах тегов или каждого такого файла.
Чем выше по тексту будет размещён код, тем быстрее он будет загружаться и отправлять информацию о просмотрах. Даже если посетитель почти сразу закроет страницу, такой просмотр, скорее всего, будет засчитан.
На что обратить внимание
Часто на одном сайте используются несколько CMS. Например, одна отвечает за содержимое сайта, а другая — за форум. Код Метрики нужно разместить в каждой CMS.
Код нужно добавить на все страницы вашего сайта без исключений. Если на каких-то страницах кода не окажется, для Метрики посетитель будет то возникать на сайте, то пропадать, и тогда в статистику попадут искажённые данные.
Если вы измените настройки кода счетчика Метрики, вам потребуется обновить код, размещённый на вашем сайте.
Если на сайт регулярно заходят посетители, вы увидите первую статистику практически сразу после установки кода на сайт. Обычно время поступления данных в отчёты не превышает трёх минут.
Нужно ли менять изначальные настройки счётчика, если вы собираетесь использовать Вебвизор?
