-
-
Save andrey-legayev/c2879927bcb4a648793ad0aea1509773 to your computer and use it in GitHub Desktop.
| <?php | |
| /** | |
| * Binary search - search element in sorted array of values and return true/false | |
| * | |
| * @param $value | |
| * @param $array array | |
| * @return bool | |
| */ | |
| function in_array_binary($value, array &$array) | |
| { | |
| // Set the left pointer to 0. | |
| $left = 0; | |
| // Set the right pointer to the length of the array -1. | |
| $right = count($array) - 1; | |
| while ($left <= $right) { | |
| // Set the initial midpoint to the rounded down value of half the length of the array. | |
| $midpoint = intdiv(($left + $right), 2); | |
| $current = $array[$midpoint]; | |
| if ($current < $value) { | |
| // The midpoint value is less than the value. | |
| $left = $midpoint + 1; | |
| } elseif ($current > $value) { | |
| // The midpoint value is greater than the value. | |
| $right = $midpoint - 1; | |
| } else { | |
| // This is the key we are looking for - we found it | |
| return true; | |
| } | |
| } | |
| // The value was not found. | |
| return false; | |
| } | |
| function test($size, $iterations) | |
| { | |
| // prepare arrays | |
| $arr = []; | |
| for ($i = 0; $i < $size; $i++) { | |
| $value = rand(); | |
| array_push($arr, $value); | |
| } | |
| // run tests | |
| $t1 = microtime(true); | |
| for ($j = 0; $j < $iterations; $j++) { | |
| $x = in_array($j, $arr); | |
| } | |
| $t1 = microtime(true) - $t1; | |
| $t2 = microtime(true); | |
| sort($arr); | |
| for ($j = 0; $j < $iterations; $j++) { | |
| $x = in_array_binary($j, $arr); | |
| } | |
| $t2 = microtime(true) - $t2; | |
| // echo results as CSV | |
| printf("%s, %d, %d, %f, %f\n", phpversion(), $size, $iterations, $t1, $t2); | |
| } | |
| echo "# PHP Version, Array Size, Iterations, in_array(), binary_search()\n"; | |
| for ($i = 1; $i <= 100000; $i = $i * 10) { | |
| test($i, 10000); | |
| } |
| #!/bin/bash | |
| for ver in 7.0 7.1 7.2 7.3; do | |
| echo "# running tests for version $ver" | |
| image=php:$ver-cli | |
| docker run --rm -v "$PWD":/src $image \ | |
| bash -c "php /src/perf-test.php" | |
| done |
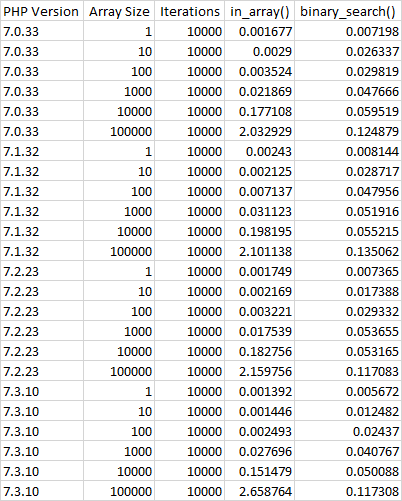
On small data sets (<10000 elements) in_array is still be faster.
It's due to the fact that in_array() is native PHP function, but binary search implemented as php code.
This is comparison - see last value in rows: "ratio"
# PHP Version, Array Size, Iterations, in_array(), binary_search(), ratio
7.3.10, 1, 10000, 0.001805, 0.006006, ratio: 0.300504
7.3.10, 10, 10000, 0.001712, 0.013662, ratio: 0.125316
7.3.10, 100, 10000, 0.003379, 0.020435, ratio: 0.165346
7.3.10, 1000, 10000, 0.019565, 0.031215, ratio: 0.626774
7.3.10, 10000, 10000, 0.163645, 0.037205, ratio: 4.398471
7.3.10, 100000, 10000, 2.107781, 0.103909, ratio: 20.284919
Thank you very detailed explanation and giving point where it's break even.
On small data sets (<10000 elements) in_array is still be faster.
probably because in_array_binary function is written on php instead of in_array :)
That break even point can be even lower. Because sort() is inside of the time counter, it is adding a lot to it. If your array comes pre-sorted or you know it is sorted the way you need then binary search will be even quicker.
@Antarian as Igor stated above it could be rewritten in c/c++ (as php module?) and be even more faster.
Also if you perform searches many times then probably it's good idea to convert input array into hashset once and then perform searches: https://www.php.net/manual/en/class.ds-set.php
Or at least do array_flip() and search by key with isset()
@andrey-legayev I have mentioned pre-sorted arrays because php is great in combination with other technologies like SQL.
Yes, if you work with larger datasets (more than 10k list items) in PHP then Ds module seems to be reasonable option. Thanks for the link.
Creating new PHP module in C, is for me on the same level as doing stuff in any other suitable language and using specialized microservice for the task.
PHP array and array functions are like good all-rounder potato, nothing special, but nothing bad. Perfectly suitable until you hit special requirements somewhere.
Note: "sort()" is included into binary search time (!)
In normal case data should be sorted before any searches.
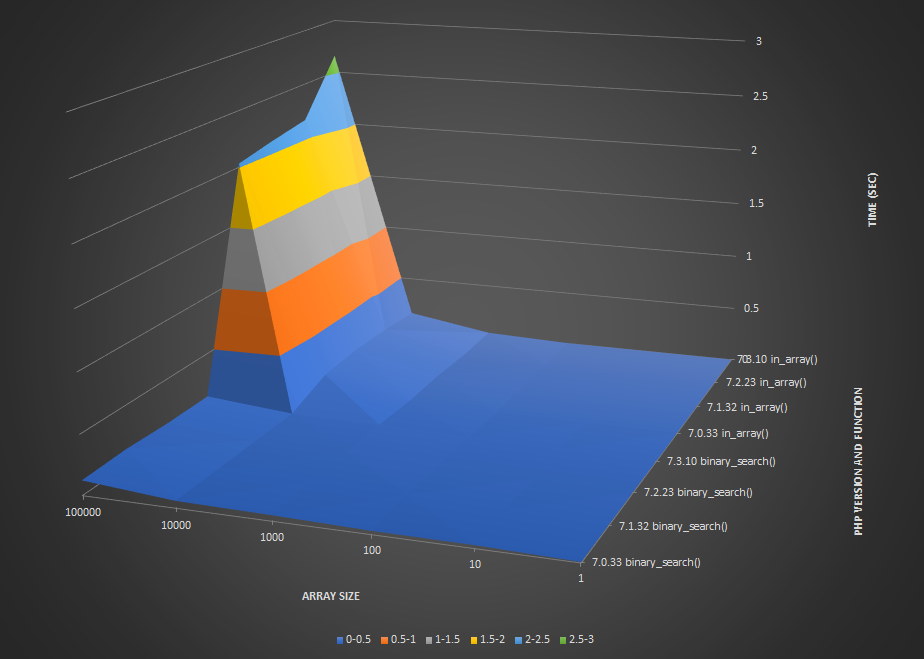
My results:
Surface diagram:
Do you still think that in_array() is good one? because it's readable?