10월 11일 ~ 12일 코엑스에서 열린 DEVIEW 2018을 정리한 글입니다.
발표내용은 SlideShare와 컨퍼런스때 메모한 내용을 참고하여 작성했습니다.
글의 길이와 가독성을 고려해서 모든 글은 두괄식으로 썼습니다.
세션별로 다음과 같은 형식을 유지하고 있습니다.
# [세션제목]
[발표자료 링크]
## [세줄요약]
## [발표내용]
## [새로 알게 된 점]
## [느낀 점]
10월 11일 ~ 12일 코엑스에서 열린 DEVIEW 2018을 정리한 글입니다.
발표내용은 SlideShare와 컨퍼런스때 메모한 내용을 참고하여 작성했습니다.
글의 길이와 가독성을 고려해서 모든 글은 두괄식으로 썼습니다.
세션별로 다음과 같은 형식을 유지하고 있습니다.
# [세션제목]
[발표자료 링크]
## [세줄요약]
## [발표내용]
## [새로 알게 된 점]
## [느낀 점]
기술은 일상의 '유익함'과 '즐거움'을 실현하기 위한 '도구' 이다
정보와 사람, 사람과 사람의 연결 이라는 철학을 주제로 함.
네이버 기술 전략의 핵심은 AI이다.
AI는 Artificial Intelligence가 아닌 Ambient Intelligence(생활 환경 지능)
환경과 상황을 인지해서 자연스럽게 제공해주는 기술.
AI의 3가지 핵심기술
네이버 서비스를 사용하는 사례들과 사용 시나리오를 짐작할 수 있었음.
연결을 강조한 플랫폼 : 네이버 지도(공간과 이동)
공간과 이동에 대한 서비스
지도: 업데이트. API, SDK 무료,
모바일(안드로이드, iOS)에서 지도 무제한, 무료로 SDK 공개.
Xdm 플랫폼 소개 https://www.naverlabs.com/storyDetail/68
NAVER LABS - AR navigation COEX demo
NAVER LABS - Hybrid HD map generation
항공사진 중첩, 3차원 지도 로드맵 생성해서 도로, 노면, 차선을 추출.
차량 카메라로 주변 신호, 노면 기호 스캔
자율주행을 위해 지도 스캔하는 기술이 인상깊었다.
로봇으로 지도 업데이트. 간판을 스캔해서 비교한 뒤 업데이트하는 영상을 보고 이런 곳에서 쓸 수 있겠구나 라는 생각을 함.
기술을 서비스에 구체적으로 사용하는 것을 보고 다른 기술들의 적용을 상상해볼 수 있었음.
일반 개발자들도 지도 SDK를 쓸 수 있는건가? 프로젝트 할 때 사용해봐야겠다!
Facebook : Event dashboard에서 시작해서 React-Native로 발전시켰고, 속도는 2배 향상시킴.
Instagram : RN 앱으로 iOS와 Android 앱을 더 빠르게 전달할 수 있음, 앞으로도 계속 RN을 사용할 계획.
Discord: 98%의 코드를 iOS와 React Native가 공유함.
"React Native가 미래다"
MVP를 만들 때 가장 가성비가 좋은 프레임워크!
리액트는 Virtual DOM에서 diff 알고리즘으로 바뀐 부분만 다시 렌더링한다.
React Native는 네이티브 뷰에서 렌더링하는 것으로 바꿈
React Native 의 쓰레드
쓰레드는 독립적으로 직접 통신 못하고 브릿지를 통해야 한다.
Javascript는 싱글 쓰레드이고, Bridge Thread는 비동기적으로 처리한다.
구조가 간결하지만 불필요한 메모리 복사가 일어난다.
해결방법 :
네이티브 호출하는 메세지를 큐에 넣어서 5ms 마다 일괄적으로 처리
페이스북이 최근에 아키텍쳐 개선하고 있다는 글 올림
UI 업데이트를 위해 멀티 쓰레드로 바로 업데이트 할 수 있다.
Production App일 땐 Expo 쓰지 않는 것 추천
애니메이션, 레이아웃은 중간에 안드로이드 확인하세요!
Optional chaining 으로 Null safety 한 코드 작성가능.
Dependency Package Lock
Flow 사용 추천!
Javascript Core의 동작 오류. 디버깅 모드에서는 V8엔진 사용 실제로는 JSCore 엔진. 이떄 오류 발생함
안드로이드 Text 위 아래 패딩 제거하는 방법 : includeFontPadding 끄기
앱 크기에 대한 걱정은 오해 Cake는 마켓에 등록된 평균보다 더 작은 크기였음.
네비게이션 모듈 선택을 잘 해야 한다.
Lottie를 사용하면 복잡한 애니메이션도 처리할 수 있다.
React Native 동작원리 - Bridge Thread와 메세지 큐, 그리고 개발 팁 모두 도움되는 지식들이었다.
인기가 정말 많았던 React Native 세션.
발표자분께서 시작하기 전에 자극적인 제목에 이목이 집중된 것 같다고 하신 말씀이 기억났다.
발표 중간에 적절한 유머 덕분에 지루하지 않았고, React Native를 바라보는 관점에서 나도 공감하는 부분이 많았다.
전에 Flow를 써서 개발했을 때 빌드타임도 오래 걸리고,
라이브러리 사용하는데 문제가 많아서 React Native를 왜 쓰는지 이해가 안간다는 생각을 했는데
내가 잘못 사용하고 있지 않았나 생각하게됨. 조금 더 제대로 공부하고 사용했더라면...하는 아쉬움을 느꼈다.
그리고 발표자분의 경험에 기반한 얘기들이어서 좋았음.
오늘의 데뷰 명언
Q: Airbnb는 React Native에서 다시 네이티브로 간다는데 역시 네이티브가 좋은거 아닌가요?
A: Airbnb만큼 회사가 커지고 나서 고민해도 되는 문제라고 생각한다.
출처 : https://twitter.com/rodumani_/status/1050214336545796096
발표자님의 생각 : 발표자 이성민님의 페이스북 게시물
2004년에 애플 WebKit에서 Canvas가 처음 구현됨.
Ian Hickson이 WHATWG에서 Canvas를 표준화 시켰다.
HTML Canvas Element는 전세계에서 30% 정도 사용되고 있다. (크로미움 기준)
브라우저는
DOM 파싱 - 어떤 모양으로 그릴지
CSS 파싱 - 레이아웃 트리 생성
Layouting - 각 엘리먼트의 위치와 사이즈를 결정
Layerization - 그리는 순서를 결정
Rendering Engine이 <button></button>을 어떻게 그릴지 알고있다.
Canvas는 개발자가 자바스크립트 코드로 그리는 것.
1000ms / 60fps = 16.7ms에 1 frame을 그려야함.
16.7ms내에 Rendering Engine, JS Engine, Graphics Library가 그림을 그려야 함.
DOM / Javascript / Painting / 그리고 Idle동안에 Canvas의 한 프레임을 Rendering 해야함.
하지만 Main Thread가 하는 일이 많아서 16.7ms동안 그림을 그리기 어렵다. -> Frame Drop이 일어난다.
DOM, JS는 브라우저에서 접근하기 어렵다. Painting에 접근해보자.
만약 화가라면
다른 화가를 고용해서 그림 그리는 일을 시킨다.
오버헤드는 생기지만 전체적으로 시간을 단축시킬 수 있다.
어디에 무엇을 그릴지 지시를 해주면 다른 화가는 지시받은 대로 그림만 그린다.
Main Thread에서 그림 그리는 방법을 Raster Thread에게 전달해준다.
Raster Thread의 그림을 합쳐서 페이지를 완성한다.
GPU를 사용하면 그림을 더 빠르게 그릴 수 있다.
JS의 부하를 줄이기 위해 다른 Thread 를 사용하면 좋겠다.
WebWorker를 사용해서 Rendering 을 따로 하고 싶었음.
<canvas></canvas>는 DOM의 일부인 HTML element여서 접근할 수 없었음. (동기화 문제)
canvas rendering를 dom으로부터 분리하고 싶다.
Offscreen Canvas API를 사용하면 DOM과 별개로 canvas rendering을 할 수 있다.
Main Thread에서는 canvas객체, offscreen canvas 객체를 가져오고
worker Thread를 생성한 뒤 offscreen canvas를 전달한다.
const canvas = document.getElementById('canvas');
const offscreen = canvas.transferControlToOffscreen();
const worker = new Worker('canvas-worker.js');
worker.postMessage({ canvas: offscreen }, [offscreen]);self.onmessage = event => {
const offscreen = event.data.canvas;
const context = canvas.getContext('2d');
function render(time) {
drawSomething(context);
requestAnimationFrame(render);
}
requestAnimationFrame(render);
};브라우저의 랜더링 과정
브라우저, 웹 개발자 관점의 개선안.
쉬운 내용은 아니었지만 목차 구성이 잘 되어있어서 발표 흐름을 쉽게 따라갈 수 있었다.
이전에 GDG WebTech와 컨트리뷰톤에서 발표를 들은 적이 있어서 배경지식을 갖고 더 수월하게 들었다.
그림그리는 화가에 대한 비유에서 이해가 더 쉽게 됐다!
크로미움 프로젝트에서 Canvas를 메인테이너이신 발표자분이어서 더 자세한 얘기를 알 수 있었다.
브라우저가 렌더링할 때 최적화하는 방법이 브라우저관점, 웹 개발자 관점 두 가지가 있다는 것.
마지막 데모영상을 보고 성능개선이 확 체감되었다.
방대한 기능 중 이중에 뭘 써야 하는지 나만 모르고 있는건가?
다들 비슷한 고민을 하고 있지 않을까? 하는 생각에서 발표를 하게 됨.
C++11부터 Modern C++이라고 한다.
왜 써야할까?
때문에 사용한다.

Move가 Copy보다 속도가 압도적으로 빠르다.
하지만 Array는 1.2배, Vector는 53.88배 차이가 난다. 이유가 뭘까? 라는 질문을 발표자분께서 하셨음.
나는 Array는 Vector와 달리 메모리에 연속적으로 할당되어서 Move와 Copy의 차이가 적다 고 생각했고, 다른 몇몇 분들도 그렇게 대답했다.
하지만 정답은 아니었음.
정답
Array는 code 영역에 메모리가 할당된다.
그래서 Move연산을 실행해도 Copy가 일어난다. 그렇기 때문에 성능차이가 거의 없다.
Modern C++ 를 사용하기 전에 고려할 점이 많다.
=> 누군가 이미 고민해주었다면? Chromium 리뷰
RValue ref T(T && t) 유니버셜 레퍼런스.
std::move() 는 RValue ref로 캐스팅std::forward() 는 LV는 LV ref, RV는 RV ref로 캐스팅. 완벽 전달자Emplace methods :
emplace(), emplace_back(), emplace_front(), emplace_hint()push_back()보다 emplace_back() 성능이 더 좋을 수 있음.noexcept :
make_move_iterator() :
auto :
auto*를 사용.std::bind() 대신 base::bind()Modern C++를 사용하면
성능, 다양한 기능, 안정성, 간결한 코딩 장점이 있음.
하지만 사용하기 전 지원환경과, 동작 유무를 모두 검토해야함.
feature에 따라 조심히 사용해야함.
Chromium base library 참고해서 사용해보는 것도 좋다.
Inline namespace
long long 대신 int32_t, int64_t 사용
Regular Expressions
Exceptions
Non-Static 클래스 멤버 초기화
Q: C++ 프로젝트 레퍼런스로 참고할 만한 곳이 있을까요?
A: C++ 처음 공부할 때 Effective C++ 책과 Effective Modern C++를 봤음.
그리고 크로미움 코드의 설계, 템플릿을 을 보고 성능개선이.
체감되었Guru들의 리뷰를 받은 코드이기 때문에 퀄리티가 높고, 다양한 설비들이 있다.
참조하고 싶은 코드가 있다면 크로미움 코드를 참고하는 것이 좋다!
Lambda에서 callback(), bind()는 마침 작업하고 있는 공부하는 부분의 패치여서 반가웠다.
발표자분 질문이 기초적인 쉬운 질문이라고 생각했는데 마지막에 답을 들었을 때 전혀 생각조차 못한 답이어서 놀랐다. 덕분에 새로운 것을 배웠음!
크로미움 얘기, C++ 얘기여서 흥미롭고 재미있게 들었다.
크로미움 팀에서 했던 고민들과 가이드라인을 참고하면 좋은 공부를 할 수 있을 것 같다.
발표 내용이 어려웠다... 다시 정리하면서 공부하는데 아직 모르는 부분이 많다.
WebAppFramework : WebApp 개발을 도와주는 Framework

file chooser함수가 사라지면서 파일첨부 기능이 동작하지 않음.
자체 엔진의 필요성을 느낌 => Chromium에 Contribution
현재 WebView를 이용하면 파편화 문제는 해결할 수 있지만 6주 업데이트 주기마다 버그를 대처해야 한다.
직접 Contribution? -> 패치 리뷰 기간이 길기 때문에 버그를 빠르게 고치기 어려움.
멀티 프로세스 구조 - 랜더러 프로세스가 죽어도 브라우저 프로세스는 살아있어서 앱이 죽지 않음.
포켓히어로즈, LinePlay, 네이버앱에 실제 적용
The higher up you start on the timeline waterfall the more work the browser has to do to get pixels on to the screen.
타임라인 워터폴의 위에서부터 시작할수록 브라우저가 스크린에서 픽셀을 가져오기 위해 해야하는 일이 많아진다.
출처:https://www.html5rocks.com/en/tutorials/speed/high-performance-animations/
새 버전의 Chromium으로 업데이트
NewSource 머지 및 빌드부터 안정화까지 최소 3달 소요됨.
Intel이 만든 WebAppFramework
사용할 때의 장점:
많은 매력적인 포인트들이 있다.
예상되는 위험
그래서 Crosswalk을 사용해서 네이버 앱에 적용시켰다.
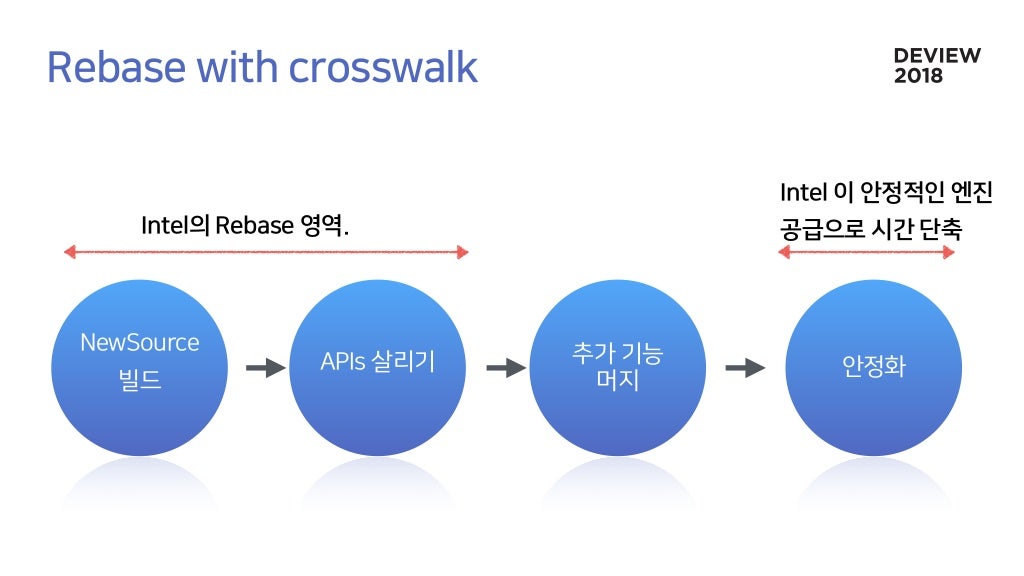
결국 1년 전 인텔이 Crosswalk 개발을 포기했다.
Crosswalk을 fork 해서 XWhale 개발을 시작.
현재 크로미움69로 리베이스중
웨일 안드로이드와 코드 중복이 많아서 통합하는중
Chromium의 빠른 개발 속도
Rebase는 힘든 숙제
안드로이드 OS update시 이슈가 발생할 여지 있음.
하지만 서비스 안정성에 기여했다고 생각함.
웹 콘텐츠를 최적화하는 방법.
오픈소스 프로젝트 사용을 공짜로 오해하는 경우가 있는데 전혀 아니라는 것을 보여주는 사례인 것 같다.
크로미움 프로젝트의 개발 속도는 빠르기로 유명한데 그 속도를 맞춰서 개발하는 것 대단하다고 생각함.
Q: 웨일 브라우저와 비슷한데 왜 파편화 되었나요? 더 일찍 통합해서 개발했으면 리소스를 줄일 수 있었을 것 같아요.
A: XWhale 개발을 먼저 시작했다. 서비스 중이다보니 합쳐지는게 더뎠다.
사용자의 패턴을 분석해서 적응하는 타이핑 분석기에 대한 논문은 있음. but 딥러닝 적용은 아니었음.
CoreML
TensorFlow Mobile
TensorFlow Lite
앱의 메모리 제한은 30MB, 남은 여유공간에 ML 모델을 올린다.
가벼워야 하고 컨버팅 가능한 모델. 제약조건이 많았다.
7주간 사내 챌린지에서 많은 알고리즘이 나왔음.
모델을 모바일에 컨버팅하는 과정부터 시작이었다.
TensorFlow + Pytorch + Keras + Caffe 로 된 모델을 모바일에서 지원하게 컨버팅!
오타 -> 정타 50%
정타 -> 오타 45%
Anchro Algorithm, Result Tuning, Ellipse Algorithm를 사용해서
오타 -> 정타 75%
정타 -> 오타 20%
모델만 만들어서 넣으면 끝날 것 같다는 착각
데이터 전/후 처리 과정이 길었다.
30번의 사용성 평가, 120번의 테스트 어플리케이션 배포
하지만 남들이 잘 걷지 않은 길을 걸으며 프로세스를 설립했다.
iOS에 모델을 적용시킨 여러 프로젝트들을 보면서 관심을 가지고 있었다.
ML을 적용시킨 서비스는 접근성이 높은 모바일에서 더 강점을 보인다고 생각했음.
모델을 컨버팅해서 적용하는데 많은 시행착오를 하고 공유해주신 것에 감사하다는 생각을 했음.
아직 초기단계여서 컨버팅하는 자료나 문서가 부족하지만 앞으로 모바일에 ML 적용한 프로젝트들이 많아져서 참고할 레퍼런스가 많아졌으면 좋겠다고 생각함.
음성 정보에서 화자의 감정, 언어, 성별, 나이를 판단할 수 있음
인증, 개인화, 디지털 법의학 등에서 쓰일 수 있음.
헤이 클로바, 음악 들려줘를 말하면,
ㅇㅇ님을 위한 추천 음악입니다. 라고 대답함.
호출어 : 헤이 클로바
명령어 : 음악 들려줘
명령어는 다양하기 떄문에 Text-dependent한 호출어를 대상으로 만들었음.
성능이 더 좋은 DNN 기반의 VGGVox, ResNet 등을 사용.
Baseline 시스템 :
음성특징 추출 - DNN에 입력 - 화자벡터를 출력 - 화자벡터로 유사도 검증.
Contrastive Loss 로 훈련
Anchor, Positive, Negative.
Anchor와 Positive는 최대한 가깝게, Negative와는 최대한 멀게 훈련.
하지만 훈련이 잘 안되었음. => Negative를 Positive와 비슷한 목소리로 사용해서 모델도 헷갈리는 목소리로 훈련시킴.
VGGVox와 ResNet
ResNet w/ Attention
Squeeze & Excitation
환경에 따라서, 발화 거리에 따라서 성능이 변화함.
등록된 화자 수에 따른 성능
Pytorch에서 Caffe2를 사용해서 연산속도 높였고
Pytorch에서 GPU를 사용할 때 비약적으로 성능 향상됨
성능개선 사항
현재 화자인식의 한계
악의적인 사용자 대처
성능 개선하는 노력 대단
상대적인 성능을 공개하는것을 보고 아직 성능이 뛰어나게 좋지는 않은건가? 하는 추측을 해봤음.
데이터 크기, 피쳐, 다른것 내부사정에 의해 공개 안해서 궁금했지만
가장 중요하다고 생각하는 모델 설명을 들을 수 있었음.
하지만 그래도 모델에 대한 이해는 잘 안됐음.
스마트 스피커의 화자인식은 넘어야 할 영역이라고 생각함.
네이버에는 음성 서비스가 많다.
음성 합성이란 Txt -> Wav 음성은 텍스트보다 정보를 더 많이 가지고 있다. (운율, 발음, 속도, 호흡)
지금까지의 네이버 음성 합성기
nVoice Concatenation Synthesis
음소를 선택한다. Target cost와 Joining? 추정한 정보와 얼마나 비슷한가 / 연결성
화자 선정 녹음 환경 사운드 엔지니어
상용화된 개인화 음성 서비스는 아직 업삳. 녹음, 발성, 발음, 분량 등등... 모델 구현 현재의 방법으로는 어렵다.
목소리가 생각보다 훨씬 더 자연스럽다고 느꼈음. 곧 상용화 할 수 있겠는데? 하는 생각. ML을 이렇게도 적용할 수 있구나! 라고 또 느낌
컨테이너 클러스터 앞에 로드밸런서와 라우터가 있다.
스태틱한 서버가 아닌 동적으로 자주 생성/삭제되는 컨테이너이기 때문에 설계할 때 고려사항 많다.
문제점과 해결방법, 리눅스 커널에서 어떻게 했는지 설명할 예정
정의 : 여러 클러스터에 수천 개 이상의 컨테이너가 운영되는 환경.
클러스터 : 리눅스 머신 1개.
Layer4 Load Balancer : 흩어진 컨테이너의 부하를 균등하게 분산.
하드웨어 Load Balancer는 Destination IP를 정적으로 설정해야 한다.
컨테이너는 수천 개 이상, IP 정보 추가,삭제, 변경이 빈번함.
만약 Load Balancer에 장애가 발생한다면? -> Load Balancer가 처리하던 Connection이 유실.
스케줄링 제대로 안된다.리눅스 머신 재부팅 된다. -> High availability하지 않다.
그래서 도커 스웜 + 쿠버네틱스로 컨테이너 클러스터 구축
소프트 L4에 IP정보 가지고 있다.
하드웨어 L4에서는 소프트 L4에서 동적으로 IP를 읽어올 수 있다.
기존 L3 라우팅 방식 한계 : 같은 비용(홉)의 경로가 여러 개 존재해도 하나의 경로만 선택한다.
BGP : L3에 라우팅 인포메이션을 동적으로 연결. 최적의 경로로 연결하는 라우팅 프로토콜
ECMP : 라우터와 S3스위치와 L4 경로의 비용이 동일할 때 한 경로만 선택하는데 그 경로에 대한 부하를 분산시켜 준다.
Hashing을 하고 Load Balancer 갯수( N ) 만큼 Modular 연산.
고가용성 측면에서 Load Balancer가 장애인 상황.
Hashing Disruption이 발생.
N의 변경으로 Hash Remapping이 발생함.
모듈러 연산의 N이 바뀌기 때문에 기존 연결이 모두 바뀌는 상황.
다른 Load Balancer들의 연결도 영향을 받는다.
Load Balancer가 다운되어도 전체 컨테이너 서비스 운영에 지장이 없어야 한다.
BGP/ECMP는 부하분산을 제공하지만 Hashing Disruption의 이슈가 남아있다.
Not Reliable(Down), Not Scalable(N이 증가할때도 동일)
그래서 도커 스웜과 쿠버네틱스
Consistent Hashing을 사용
N에 변동이 있을 때 K/N 만큼의 디스럽션을 보장.
K: connection, N: Number of Load Balancers
Circular 배열에 넣어서 변동이 생길때 최소한으로 재할당한다. 하지만 효율적인 로드밸런싱은 보장하지 않음.
Permutation
Permu 테이블의 정보를 Lookup테이블에 넣는다.
이 과정을 다 마치면 거의 동등한 수의 백엔드 테이블로 Load Balancing이 된다.
B1이 다운되어도 Permu 테이블은 해싱기반이기 떄문에 변하지 않음.
Lookup 테이블의 B1부분을 다시 채울 때 사라진 B1에 대해서만 바뀐다. (K/N 보장)
하지만 맥레브를 사용하기 위해서 모든 기능을 다 구현해야한다...?
IPVS : IP Virtual Server 리눅스의 로드밸런서 소프트웨어. Linux Kernel의 Netfilter를 사용하여 구현됨.
IPVS에 Packet forwarding, packet processing, backend selection은 구현되어 있었다.
IPVS에 Consistent Hashing만 구현하면 됨!
리눅스에서 스케줄링 알고리즘을 모듈로 제공하기 때문에
전체 커널 컴파일 없이 Maglev 모듈만 컴파일을 해서 개발을 진행함.
그래서 구현한 뒤 Linux Kernel에 Contribution.
6개월동안 500line 코드작성.
생각하지 못한 리눅스 커널의 작은 메모리 공간까지도 신경쓰면서 리뷰받음.
하드웨어 : IPVS + MH
소프트웨어 : BGP/ECMP
한대가 다운되어도 Lookup테이블을 보고 K/N만 끊긴다.
리눅스 4.18버전부터 사용가능!
서버 아키텍처는 항상 관심을 가지고 있는 분야!
모르는 얘기들까지도 재밌게 들었음. 그림 덕분에 한눈에 잘 들어옴.
스위치, L4 를 이번 기회에 처음부터 다시 공부했다.
해싱으로 K/N의 커넥션이 끊기는 것을 보장한다는 아이디어에 정말 감탄...
리눅스 커널에 머지하기까지 6개월이 걸리셨다니 그 과정을 거치고 컨트리뷰션한게 대단하다고 느낌















































