-
-
Save cooldil/0b2c5ee22befbbfcdefd06c9cf2b7a98 to your computer and use it in GitHub Desktop.
| import requests, pickle | |
| from datetime import datetime | |
| import json, pytz | |
| import pandas as pd | |
| from influxdb import DataFrameClient | |
| # Set "static" variables | |
| login_url = "https://monitoring.solaredge.com/solaredge-apigw/api/login" | |
| panels_url = "https://monitoring.solaredge.com/solaredge-web/p/playbackData" | |
| DAILY_DATA = "4" | |
| WEEKLY_DATA = "5" | |
| # Set "customizable" variables. Update as appropriate | |
| COOKIEFILE = 'solaredge.cookies' | |
| TIMEPERIOD = DAILY_DATA | |
| SOLAREDGE_USER = "" # web username | |
| SOLAREDGE_PASS = "" # web password | |
| SOLAREDGE_SITE_ID = "" # site id | |
| INFLUXDB_IP = "" | |
| INFLUXDB_PORT = 8086 | |
| INFLUXDB_DATABASE = "" | |
| INFLUXDB_SERIES = "optimizers" | |
| INFLUXDB_RETENTION_POLICY = "autogen" | |
| session = requests.session() | |
| try: # Make sure the cookie file exists | |
| with open(COOKIEFILE, 'rb') as f: | |
| f.close() | |
| except IOError: # Create the cookie file | |
| session.post(login_url, headers = {"Content-Type": "application/x-www-form-urlencoded"}, data={"j_username": SOLAREDGE_USER, "j_password": SOLAREDGE_PASS}) | |
| panels = session.post(panels_url, headers = {"Content-Type": "application/x-www-form-urlencoded", "X-CSRF-TOKEN": session.cookies["CSRF-TOKEN"]}, data={"fieldId": SOLAREDGE_SITE_ID, "timeUnit": TIMEPERIOD}) | |
| try: | |
| with open(COOKIEFILE, 'wb') as f: | |
| pickle.dump(session.cookies, f) | |
| f.close() | |
| except IOError: | |
| print('Unable to create cookie file (readonly filesystem?): ' + COOKIEFILE) | |
| try: | |
| with open(COOKIEFILE, 'rb') as f: | |
| session.cookies.update(pickle.load(f)) | |
| except IOError: | |
| print('Unable to open cookie file: ' + COOKIEFILE) | |
| print('Will continue running with new login...') | |
| session.post(login_url, headers = {"Content-Type": "application/x-www-form-urlencoded"}, data={"j_username": SOLAREDGE_USER, "j_password": SOLAREDGE_PASS}) | |
| # Get the cookie expiration | |
| for cookie in session.cookies: | |
| if cookie.name == 'SolarEdge_SSO-1.4': | |
| cookie_expiration = cookie.expires | |
| panels = session.post(panels_url, headers = {"Content-Type": "application/x-www-form-urlencoded", "X-CSRF-TOKEN": session.cookies["CSRF-TOKEN"]}, data={"fieldId": SOLAREDGE_SITE_ID, "timeUnit": TIMEPERIOD}) | |
| if (panels.status_code != 200) or (datetime.now() > datetime.fromtimestamp(cookie_expiration)): # Update cookie if expired | |
| session.post(login_url, headers = {"Content-Type": "application/x-www-form-urlencoded"}, data={"j_username": SOLAREDGE_USER, "j_password": SOLAREDGE_PASS}) | |
| panels = session.post(panels_url, headers = {"Content-Type": "application/x-www-form-urlencoded", "X-CSRF-TOKEN": session.cookies["CSRF-TOKEN"]}, data={"fieldId": SOLAREDGE_SITE_ID, "timeUnit": TIMEPERIOD}) | |
| if (panels.status_code != 200): | |
| exit() # Terminate if unable to get panel data | |
| f.close() | |
| try: | |
| with open(COOKIEFILE, 'wb') as f: | |
| pickle.dump(session.cookies, f) | |
| f.close() | |
| except IOError: | |
| print('Unable to update expired cookie file [' + str(datetime.fromtimestamp(cookie_expiration)) + '] (readonly filesystem?): ' + COOKIEFILE) | |
| response = panels.content.decode("utf-8").replace('\'', '"').replace('Array', '').replace('key', '"key"').replace('value', '"value"') | |
| response = response.replace('timeUnit', '"timeUnit"').replace('fieldData', '"fieldData"').replace('reportersData', '"reportersData"') | |
| response = json.loads(response) | |
| data = {} | |
| for date_str in response["reportersData"].keys(): | |
| date = datetime.strptime(date_str, '%a %b %d %H:%M:%S GMT %Y') | |
| date = pytz.timezone('America/New_York').localize(date).astimezone(pytz.utc) | |
| for sid in response["reportersData"][date_str].keys(): | |
| for entry in response["reportersData"][date_str][sid]: | |
| if entry["key"] not in data.keys(): | |
| data[entry["key"]] = {} | |
| data[entry["key"]][date] = float(entry["value"].replace(",", "")) | |
| df = pd.DataFrame(data) | |
| conn = DataFrameClient(INFLUXDB_IP, INFLUXDB_PORT, "", "", INFLUXDB_DATABASE) | |
| conn.write_points(df, INFLUXDB_SERIES, retention_policy=INFLUXDB_RETENTION_POLICY) |
Hi
thank you for the advice. Tested the script results (before Influx) against the Solar Edge Web Portal (CSV export). It's quite similar, but not exactly the same. I assume it's some different roundings... See below:
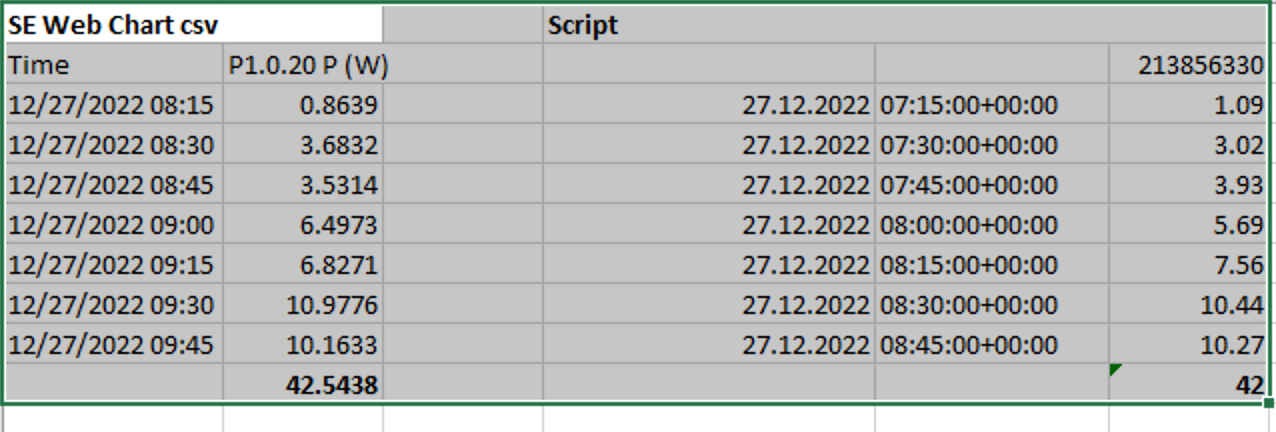
I'm really not familiar with python, could you give me a hint where at the script you choose the data to be extracted and could the other data (Energy, Current, Voltage Panel, Voltage Optimizer) as well be extracted?
Merry christmay
Hi @cooldil I'm wondering whether you happen to have a list of API parameters that I could use alongside those that you programmed in this GIST. Or, could you confirm that these are the only ones?
Hi
I am wondering how to find this url on dashboard. Thanks!
panels_url = "https://monitoring.solaredge.com/solaredge-web/p/playbackData"
Hi I am wondering how to find this url on dashboard. Thanks! panels_url = "https://monitoring.solaredge.com/solaredge-web/p/playbackData"
The URL you referenced is called when you change over to the Layout area and then click on "Show playback". This brings up a "slider view" where you can see what the output of each of your panels was for any given 15 minute interval.
Thanks for your reply. It works well for me!
Another question, it seems that we are only able to retrive data on current day. Cause the "Show playback" can't display historical daily data. Am I right? And do you have any idea to retrive historical panel data. Thanks.
the ouptput dataframe's column names are be like:
197469474 | 197469507 | 197469573 | 197469606
I am wondering how to match it with the module number on the dashboard. Thanks again!
Thanks for your reply. It works well for me! Another question, it seems that we are only able to retrive data on current day. Cause the "Show playback" can't display historical daily data. Am I right? And do you have any idea to retrive historical panel data. Thanks.
You can go back upto a week. Change the TIMEPERIOD variable to "WEEKLY_DATA"
the ouptput dataframe's column names are be like: 197469474 | 197469507 | 197469573 | 197469606
I am wondering how to match it with the module number on the dashboard. Thanks again!
See my earlier comment: https://gist.github.com/cooldil/0b2c5ee22befbbfcdefd06c9cf2b7a98?permalink_comment_id=4408019#gistcomment-4408019
Hello @cooldil, thanks for sharing your snippet and insights - very helpful and useful! I just added some code to automatically extract the logical IDs (in my case 1.1.1. – 1.1.29.) and serial numbers of optimizers from SE. Hope that might helpful for somebody else.
Here is the code:
# code snippet (2025-06-04 by Thomas Hermann) to retrieve logical IDs
# (e.g. 1.1.1 -- 1.1.29) and serial numbers for panel optimizers from SE,
# Instruction: add the following code after df = pd.DataFrame(data) in cooldils
# snippet (s. line 79). Disclaimer: I did not use/test this with influxdb !
#
# The code requests/extracts information from SE and persists it as dict into
# a pickle file. If that file already exists, it is simply loaded.
# As SE keys stay identical, getting the info needs to be done only once,
#
# Note that API calls work only directly after retrieving data, as otherwise the cookie
# would be outdated.
#
# Results:
# - SE_keys_to_ids is a dictionary where keys are the SE keys of the panels, and values
# are tuples containing (logical_id, serial_nr).
try:
with open("SE_keys_to_ids.pickle", 'rb') as fp:
SE_keys_to_ids = pickle.load(fp)
except FileNotFoundError:
SE_keys_to_ids = {}
for module_key in df.columns: # column names are SE keys
print(f"get logical ID and serial nr for SE_key {module_key}")
res = session.post(
"https://monitoring.solaredge.com/solaredge-web/p/systemData",
headers={
"Content-Type": "application/x-www-form-urlencoded",
"X-CSRF-TOKEN": session.cookies["CSRF-TOKEN"],
},
data=dict(
fieldId=SOLAREDGE_SITE_ID,
reporterId=module_key,
activeTab="0",
isPublic="false",
type="panel",
)
)
# res.text contains a javascript file which contains
# as first statement ```SE.systemData = {...}```, a
# dictionary definition which is evaluted in the next line
# a bit quick and dirty...
module_dict = eval(res.text.split("\n")[11][16:-1])
logical_id = module_dict['description'].split()[1]
serial_nr = module_dict['serialNumber']
SE_keys_to_ids[module_key] = (logical_id, serial_nr)
# all information extracted, lets safe pickle file
with open("SE_keys_to_ids.pickle", 'wb') as fp:
pickle.dump(SE_keys_to_ids, fp)
print("Loading, resp. extracting SE_keys_to_ids completed")
# set proper df column names (replacing SE_keys by panel name)
df.columns = [ SE_keys_to_ids[mkey][0] for mkey in df.columns]Hello @cooldil, thanks for sharing your snippet and insights - very helpful and useful! I just added some code to automatically extract the logical IDs (in my case 1.1.1. – 1.1.29.) and serial numbers of optimizers from SE. Hope that might helpful for somebody else.
Here is the code:
# code snippet (2025-06-04 by Thomas Hermann) to retrieve logical IDs # (e.g. 1.1.1 -- 1.1.29) and serial numbers for panel optimizers from SE, # Instruction: add the following code after df = pd.DataFrame(data) in cooldils # snippet (s. line 79). Disclaimer: I did not use/test this with influxdb ! # # The code requests/extracts information from SE and persists it as dict into # a pickle file. If that file already exists, it is simply loaded. # As SE keys stay identical, getting the info needs to be done only once, # # Note that API calls work only directly after retrieving data, as otherwise the cookie # would be outdated. # # Results: # - SE_keys_to_ids is a dictionary where keys are the SE keys of the panels, and values # are tuples containing (logical_id, serial_nr). try: with open("SE_keys_to_ids.pickle", 'rb') as fp: SE_keys_to_ids = pickle.load(fp) except FileNotFoundError: SE_keys_to_ids = {} for module_key in df.columns: # column names are SE keys print(f"get logical ID and serial nr for SE_key {module_key}") res = session.post( "https://monitoring.solaredge.com/solaredge-web/p/systemData", headers={ "Content-Type": "application/x-www-form-urlencoded", "X-CSRF-TOKEN": session.cookies["CSRF-TOKEN"], }, data=dict( fieldId=SOLAREDGE_SITE_ID, reporterId=module_key, activeTab="0", isPublic="false", type="panel", ) ) # res.text contains a javascript file which contains # as first statement ```SE.systemData = {...}```, a # dictionary definition which is evaluted in the next line # a bit quick and dirty... module_dict = eval(res.text.split("\n")[11][16:-1]) logical_id = module_dict['description'].split()[1] serial_nr = module_dict['serialNumber'] SE_keys_to_ids[module_key] = (logical_id, serial_nr) # all information extracted, lets safe pickle file with open("SE_keys_to_ids.pickle", 'wb') as fp: pickle.dump(SE_keys_to_ids, fp) print("Loading, resp. extracting SE_keys_to_ids completed") # set proper df column names (replacing SE_keys by panel name) df.columns = [ SE_keys_to_ids[mkey][0] for mkey in df.columns]
Thomas you are a life saver! Thank you for the solution!
The script returns the Power values (technically averaged over a 15 minute period since that is a granularity that SE provides via the monitoring site). Since the values are only updated/published very 15 minutes or so, there is no value in running the script more often than every 15 minutes.
Run the script over a 24 hour period and see if the data stored in InfluxDB matches what is on the SE site....