https://debezium.io/blog/2021/10/20/using-debezium-create-data-lake-with-apache-iceberg/
今日では、分析、レポート、機械学習のニーズに合わせてデータレイクを構築するのが一般的です。
このブログ記事では、データレイクを構築するシンプルな方法をご紹介します。 このソリューションでは、Debeziumベースのリアルタイムデータパイプラインを使用し、ACIDトランザクションとSQL更新をサポートし、 高いスケーラビリティを実現します。 また、データフィードの構築にApache KafkaやApache Sparkアプリケーションは不要であるため、ソリューション全体の複雑さを軽減できます。
まず、データレイクの概念について簡単に説明しましょう。 データレイクとは、「通常、ソースシステムデータ、センサーデータ、ソーシャルデータなどの生のコピーを含むデータの一元的な保管場所」です。 データを加工したり、様々な分析を実行したりすることなく、そのままの状態でデータを保存できます。
運用データは通常、リレーショナルデータベースまたはNoSQLデータストアに保存されるため、データをどのようにデータレイクに伝播させるかが問題となります。 ここで登場するのがDebezium Server Icebergプロジェクトです。 DebeziumとApache Icebergをベースとするこのプロジェクトは、ソースデータベースからのリアルタイムのデータ変更イベントを処理し、 Icebergがサポートする任意のオブジェクトストレージにアップロードできます。 それでは、この2つのプロジェクトについて詳しく見ていきましょう。
Debeziumは、変更データキャプチャのためのオープンソースの分散プラットフォームです。 Debeziumは、データベースのトランザクションログから変更イベントを抽出し、 JSON、Apache Avro、Google Protocol Buffersなどの様々なフォーマットを使用して、 イベントストリーミングプラットフォーム経由でコンシューマーに配信します。 Debeziumは主にApache KafkaおよびKafka Connectで使用されます。 しかし、Debezium Serverを介して、Kinesis、Google Pub/Sub、Pulsarなどの他のメッセージングインフラストラクチャのユーザーもDebeziumの変更データキャプチャ機能を利用できます。 現在サポートされている配信先はこちらで確認できます。
Apache Icebergは、「大規模な分析データセット向けのオープンなテーブル形式です。 Icebergは、SQLテーブルと同様に動作する高性能なテーブル形式を使用して、Spark、Trino、PrestoDB、Flink、Hiveなどのコンピューティングエンジンにテーブルを追加します。」ACID挿入に加え、行レベルの削除と更新もサポートしています。 スキーマやパーティション仕様などのテーブルメタデータ、およびテーブルデータを格納するデータファイルを管理するためのJava APIも提供しています。
Apache Icebergには、データファイルと削除ファイルという概念があります。 データファイルは、Icebergが実際のデータを保持するためにバックグラウンドで使用するファイルです。 削除ファイルは、既存のデータファイルで削除された行をエンコードするための不変ファイルです。 これにより、Icebergは不変データファイル内の個々の行を、ファイルを書き換えることなく削除/置換します。 Debezium Server Icebergの場合、これらは不変のApache Parquetファイルです。 これは、「CSVやTSVファイルなどの行ベースのファイルと比較して、 効率的かつパフォーマンスの高いフラットな列指向のデータストレージ形式」として設計された形式です。
Debezium Server は新しいシンク アダプターを実装するための SPI を提供しており、 これが Apache Iceberg コンシューマーの作成に使用される拡張ポイントです。
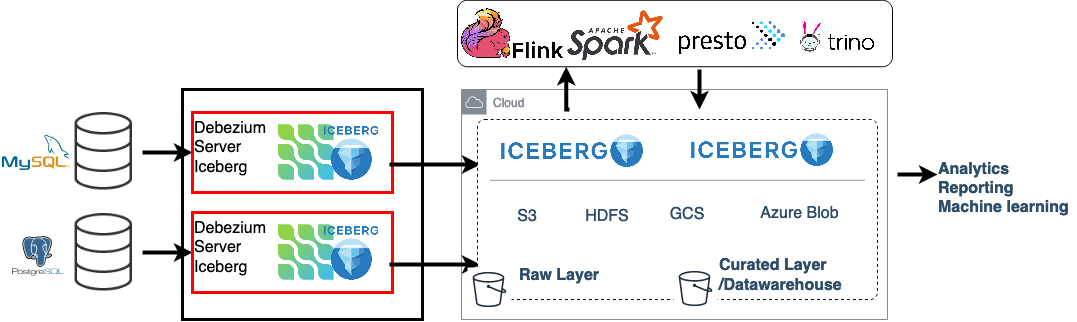
Icebergコンシューマーは、CDC変更イベントをIcebergデータファイルに変換し、Iceberg Java APIを使用して宛先テーブルにコミットします。 また、各Debeziumソーストピックを宛先Icebergテーブルにマッピングします。
指定されたIceberg宛先テーブルが見つからない場合、コンシューマーは変更イベントスキーマを使用してテーブルを作成します。
さらに、イベントスキーマは変更イベント自体を同等のIcebergレコードにマッピングするために使用されます。
そのため、debezium.format.value.schemas.enable 構成オプションを設定する必要があります。
Debeziumの変更イベントがIcebergレコードに記録されると、スキーマはデータから削除されます。
大まかに言うと、変更イベントは次のように処理されます。受信したイベントのバッチごとに、以下の処理が行われます。
- イベントは宛先の Iceberg テーブルごとにグループ化されます 各グループには、同じデータ スキーマを共有する単一のソース テーブルからの変更イベントのリストが含まれます
- 各目的地のイベントはアイスバーグレコードに変換されます
- Iceberg レコードは Iceberg データとして保存され、ファイルを削除します (削除ファイルは、コンシューマーが upsert モードで実行されている場合にのみ作成されます)
- ファイルは宛先のIcebergテーブルにコミットされます(つまり、宛先ストレージにアップロードされます)
- 処理された変更イベントはDebeziumで処理済みとしてマークされます
以下は、Iceberg アダプタで Debezium Server を使用するための完全な構成例です。
debezium.sink.type=iceberg
# run with append mode
debezium.sink.iceberg.upsert=false
debezium.sink.iceberg.upsert-keep-deletes=true
debezium.sink.iceberg.table-prefix=debeziumcdc_
debezium.sink.iceberg.table-namespace=debeziumevents
debezium.sink.iceberg.fs.defaultFS=s3a://S3_BUCKET);
debezium.sink.iceberg.warehouse=s3a://S3_BUCKET/iceberg_warehouse
debezium.sink.iceberg.type=hadoop
debezium.sink.iceberg.catalog-name=mycatalog
debezium.sink.iceberg.catalog-impl=org.apache.iceberg.hadoop.HadoopCatalog
# enable event schemas
debezium.format.value.schemas.enable=true
debezium.format.value=json
# complex nested data types are not supported, do event flattening. unwrap message!
debezium.transforms=unwrap
debezium.transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
debezium.transforms.unwrap.add.fields=op,table,source.ts_ms,db
debezium.transforms.unwrap.delete.handling.mode=rewrite
debezium.transforms.unwrap.drop.tombstones=trueデフォルトでは、Iceberg コンシューマーは upsert モード (debezium.sink.iceberg.upsert が true に設定) で実行されています。
つまり、ソース テーブルで行が更新されると、宛先の行は新しい更新バージョンに置き換えられます。
また、ソースから行が削除されると、宛先からも削除されます。
upsert モードを使用すると、宛先のデータはソース データと同一に保持されます。
upsert モードは Iceberg の等価削除機能を使用し、Debezium 変更データ イベントのキー (ソース テーブルの主キーから派生) を使用して削除ファイルを作成します。
データの重複を回避するために、各バッチで重複排除が行われ、レコードの最後のバージョンのみが保持されます。
たとえば、単一のイベント バッチで、同じレコードが 2 回出現する可能性があります。1 回は挿入時、もう 1 回は更新時です。
upsert モードでは、常に最後に抽出されたレコードのバージョンが Iceberg に保存されます。
ソース テーブルで主キーが定義されておらず、他の手段で利用できるキー情報 (Debezium で定義された一意のキーやカスタム メッセージ キーなど) もない場合は、
コンシューマーはこのテーブルに対してappend モードを使用することに注意してください (以下を参照)。
ユースケースによっては、削除されたレコードをソフト削除として保持しておくことが有効な場合があります。
これは、debezium.sink.iceberg.upsert-keep-deletes オプションを true に設定することで実現できます。
この設定により、削除されたレコードの最新バージョンが宛先の Iceberg テーブルに保持されます。
false に設定すると、削除されたレコードは宛先テーブルから削除されます。
これは最もシンプルな操作モードで、debezium.sink.iceberg.upsert を false に設定することで有効になります。
Debezium Server Iceberg を追加モードで使用すると、受信したすべてのレコードが宛先テーブルに追加されます。
データの重複排除やレコードの削除は行われません。追加モードでは、レコードの変更履歴全体を分析できます。
リアルタイムイベントを消費し、その後別の圧縮ジョブでデータ圧縮を行うことも可能です。 Icebergは、パフォーマンスを向上させるために、データとメタデータファイルの圧縮をサポートしています。
Debeziumはデータベースイベントをリアルタイムで抽出・配信するため、Icebergのテーブルへのコミットが頻繁に発生し、 小さなファイルが大量に生成される可能性があります。 これはバッチ処理には最適ではなく、特にほぼリアルタイムのデータフィードで十分な場合には最適ではありません。 この問題を回避するには、コミットごとのバッチサイズを増やすことができます。
MaxBatchSizeWait モードを有効にすると、Iceberg コンシューマーは Debezium メトリクスを使用してバッチサイズを最適化します。
Debezium の内部イベントキューの現在のサイズを定期的に取得し、max.batch.size に達するまで待機します。
待機時間中、Debezium イベントはメモリ(Debezium の内部キュー)に収集されます。
これにより、各コミット(処理されるイベントセット)でより多くのレコードが処理され、バッチサイズが一定になります。
最大待機時間とチェック間隔は、debezium.sink.batch.batch-size-wait.max-wait-ms プロパティと debezium.sink.batch.batch-size-wait.wait-interval-ms プロパティによって制御されます。
これらの設定は、Debezium の debezium.source.max.queue.size プロパティと debezium.source.max.batch.size プロパティと組み合わせて設定する必要があります。
関連するすべての設定の例を次に示します。
debezium.sink.batch.batch-size-wait=MaxBatchSizeWait
debezium.sink.batch.batch-size-wait.max-wait-ms=60000
debezium.sink.batch.batch-size-wait.wait-interval-ms=10000
debezium.sink.batch.metrics.snapshot-mbean=debezium.postgres:type=connector-metrics,context=snapshot,server=testc
debezium.sink.batch.metrics.streaming-mbean=debezium.postgres:type=connector-metrics,context=streaming,server=testc
# increase max.batch.size to receive large number of events per batch
debezium.source.max.batch.size=50000
debezium.source.max.queue.size=400000この時点で、データレイクの生データレイヤー(データ重複排除機能やほぼリアルタイムのパイプライン機能を含む)がロードされています。 その上にキュレーションされたレイヤー(分析レイヤーまたはデータウェアハウスレイヤーと呼ばれることもあります)を構築するのは非常に簡単です。 分析レイヤーでは、生データが分析要件を満たすように準備されます。 通常、生データは再編成、クレンジング、バージョン管理(下の例を参照)、集計され、ビジネスロジックが適用されます。 スケーラブルな処理エンジンを介してSQLを使用することが、この種のデータ変換を行う最も一般的な方法です。
たとえば、Spark SQL (または PrestoDB、Trino、Flink など) を使用して、 最も一般的に使用されるデータ ウェアハウス テーブル タイプである、ゆっくり変化するディメンションを簡単にロードできます。
MERGE INTO dwh.consumers t
USING (
-- new data to insert
SELECT customer_id, name, effective_date, to_date('9999-12-31', 'yyyy-MM-dd') as end_date
FROM debezium.consumers
UNION ALL
-- update exiting records. close end_date
SELECT t.customer_id, t.name, t.effective_date, s.effective_date as end_date
FROM debezium.consumers s
INNER JOIN dwh.consumers t on s.customer_id = t.customer_id AND t.current = true
) s
ON s.customer_id = t.customer_id AND s.effective_date = t.effective_date
-- close last records/versions.
WHEN MATCHED
THEN UPDATE SET t.current = false, t.end_date = s.end_date
-- insert new versions and new data
WHEN NOT MATCHED THEN
INSERT(customer_id, name, current, effective_date, end_date)
VALUES(s.customer_id, s.name, true, s.effective_date, s.end_date);追加のデータレイクレイヤーは、新しいデータで定期的に更新する必要がある場合があります。 これを行う最も簡単な方法は、SQLのupdateまたはdeleteステートメントを使用することです。 Icebergは、以下のSQL操作もサポートしています。
INSERT INTO prod.db.table SELECT ...;
DELETE FROM prod.db.table WHERE ts >= '2020-05-01 00:00:00' and ts < '2020-06-01 00:00:00';
DELETE FROM prod.db.orders AS t1 WHERE EXISTS (SELECT order_id FROM prod.db.returned_orders WHERE t1.order_id = order_id;
UPDATE prod.db.all_events
SET session_time = 0, ignored = true
WHERE session_time < (SELECT min(session_time) FROM prod.db.good_events));DebeziumとApache IcebergをベースにしたDebezium Server Icebergは、データレイク向けの低レイテンシなデータ取り込みパイプラインを非常に簡単に構築できます。 このプロジェクトはApache 2.0ライセンスに基づく完全なオープンソースです。 Debezium Server Icebergはまだ若いプロジェクトであり、改善すべき点が残っています。 ぜひお気軽にテスト、フィードバック、機能リクエストの提出、プルリクエストの送信を行ってください。 このプロジェクトでは、さらに多くの例をご覧になり、IcebergとSparkの実験を始めることができます。