CREATE TABLE "table_name" (
"id" uuid DEFAULT uuid_generate_v4(),
"created_at" TIMESTAMPTZ NOT NULL DEFAULT NOW(),
"updated_at" TIMESTAMPTZ NOT NULL DEFAULT NOW(),
PRIMARY KEY ("column", "other_column"),
UNIQUE ("column", "other_column"),
FOREIGN KEY ("column") REFERENCES "other_table_name"("column"),
FOREIGN KEY ("column") REFERENCES "other_table_name"("column") ON DELETE CASCADE,
FOREIGN KEY ("column") REFERENCES "other_table_name"("column") ON UPDATE CASCADE
);
CREATE INDEX ON "table_name" ("column", "other_column");DROP TABLE IF EXISTS "table_name" CASCADE;Add UUID suport do
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";Relationship Notes
- One-to-One A User has ONE address
- One-to-Many A Book has MANY reviews
- Many-to-Many A user has MANY books and a book has MANY users
A one-to-one relationship between two entities exists when a particular entity instance exists in one table, and it can have only one associated entity instance in another table.
Example: A user has only one address, and an address belongs to only one user.
In the database world, this sort of relationship is implemented like this: the id that is the PRIMARY KEY of the users table is used as both the FOREIGN KEY and PRIMARY KEY of the addresses table.
CREATE TABLE users (
id serial,
username VARCHAR(25) NOT NULL,
enabled boolean DEFAULT TRUE,
last_login timestamp NOT NULL DEFAULT NOW(),
PRIMARY KEY (id)
);
/*
one to one: User has one address
*/
CREATE TABLE addresses (
user_id int NOT NULL,
street VARCHAR(30) NOT NULL,
city VARCHAR(30) NOT NULL,
state VARCHAR(30) NOT NULL,
PRIMARY KEY (user_id),
CONSTRAINT fk_user_id FOREIGN KEY (user_id) REFERENCES users (id)
);
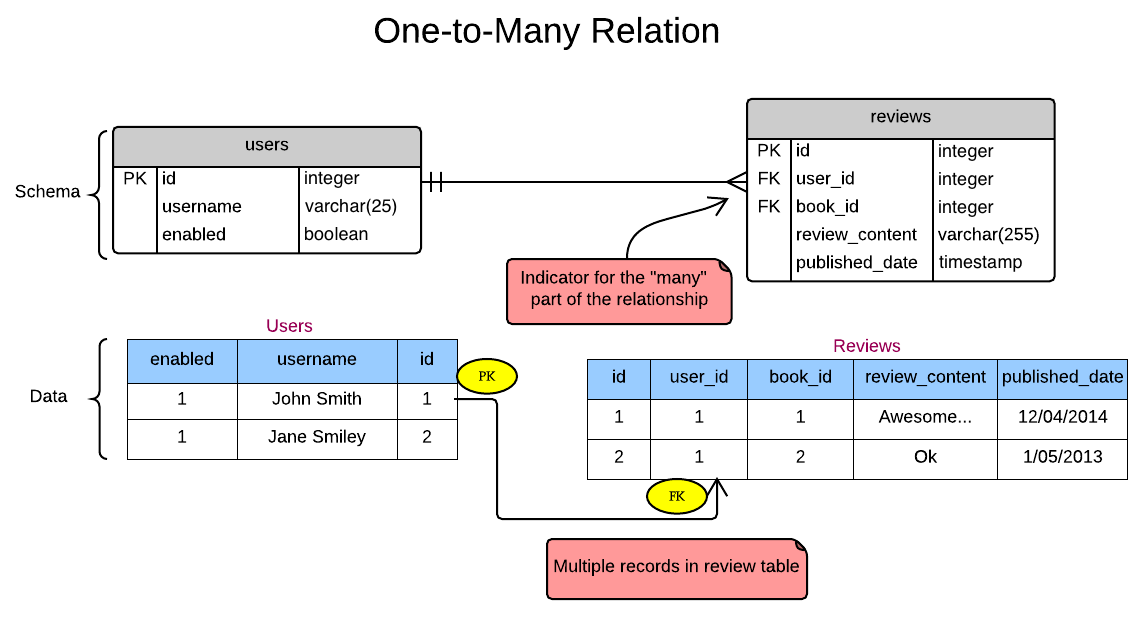
A one-to-many relationship exists between two entities if an entity instance in one of the tables can be associated with multiple records (entity instances) in the other table. The opposite relationship does not exist; that is, each entity instance in the second table can only be associated with one entity instance in the first table.
Example: A book has many reviews. A review belongs to only one book.
In the database world, this sort of relationship is implemented by ensuring that the book_id that is the PRIMARY KEY of the books table is a FOREIGN KEY of the reviews table
CREATE TABLE books (
id serial,
title VARCHAR(100) NOT NULL,
author VARCHAR(100) NOT NULL,
published_date timestamp NOT NULL,
isbn int,
PRIMARY KEY (id),
UNIQUE (isbn)
);
/*
one to many: Book has many reviews
*/
DROP TABLE IF EXISTS reviews;
CREATE TABLE reviews (
id serial,
book_id int NOT NULL,
user_id int NOT NULL,
review_content VARCHAR(255),
rating int,
published_date timestamp DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id),
FOREIGN KEY (book_id) REFERENCES books(id) ON DELETE CASCADE,
FOREIGN KEY (user_id) REFERENCES users(id) ON DELETE CASCADE
);NOTE: CURRENT_TIMESTAMP is an alias for the NOW() function. They can both be used to set the default of a timestamp as the current date and time. Notice how CURRENT_TIMESTAMP doesn't use parentheses while NOW() does. This has to do with keeping certain functions compatible with SQL standard. You'll almost always find that functions not specific to PostgreSQL use parentheses. PostgreSQL specific functions may have functions with or without parentheses.
A many-to-many relationship exists between two entities if for one entity instance there may be multiple records in the other table and vice versa.
Example: A user has many books checked out or may have checked them out in the past. A book has many users that have checked a book out.
In the database world, this sort of relationship is implemented by introducing a third cross-reference table, that holds the relationship between the two entities, which is the PRIMARY KEY of the books table and the PRIMARY KEY of the user table.
Look at the line PRIMARY KEY (user_id, book_id). The primary key is not a single key, but a composite key based on user_id and book_id. Therefore, the pair has to be unique.
CREATE TABLE users_books (
user_id int NOT NULL,
book_id int NOT NULL,
checkout_date timestamp,
return_date timestamp,
PRIMARY KEY (user_id, book_id),
FOREIGN KEY (user_id) REFERENCES users(id) ON UPDATE CASCADE,
FOREIGN KEY (book_id) REFERENCES books(id) ON UPDATE CASCADE
);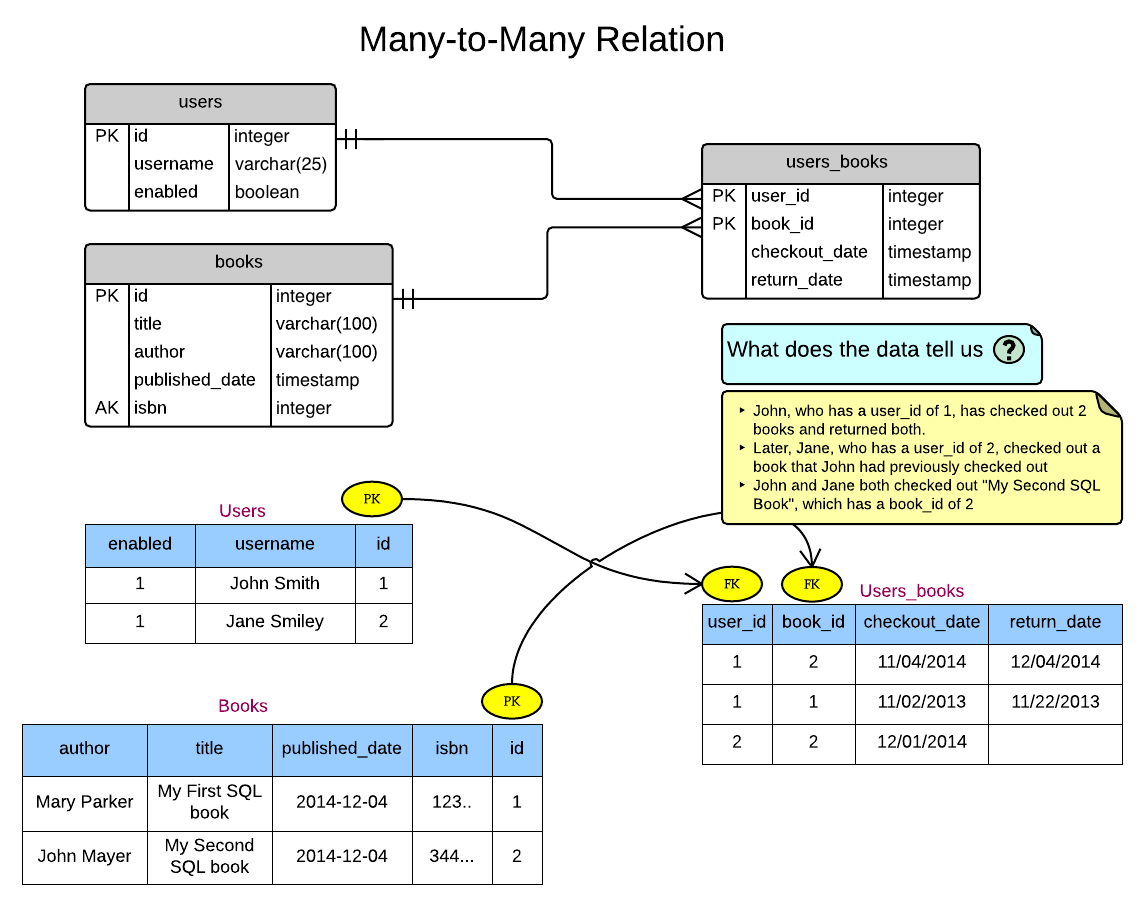
We created a many-to-many relationship, in which our primary key was made of two columns. The user_id and the book_id both together formed the primary key for the cross reference table as can be seen in this line of the SQL statement.
PRIMARY KEY (user_id, book_id)CREATE TABLE users_books (
user_id int NOT NULL ,
book_id int NOT NULL,
checkout_date timestamp,
return_date timestamp,
PRIMARY KEY (user_id, book_id),
FOREIGN KEY (user_id) REFERENCES users(id) ON UPDATE CASCADE,
FOREIGN KEY (book_id) REFERENCES books(id) ON UPDATE CASCADE
);Besides the Primary Key, a database also allows applying a Unique constraint on any column in the database. For example, in the books table, we may choose to not only have the book_id as a unique primary key, but also need to store the book's ISBN number. The ISBN, International Standard Book Number is a 10 digit unique number for a book. We can choose to design our database to make this column unique. Even though this is not a primary key, duplicate ISBNs will not be allowed in the books table, and the data quality will be maintained.
CREATE TABLE books (
id serial,
title VARCHAR(100) NOT NULL,
author VARCHAR(100) NOT NULL,
published_date timestamp NOT NULL,
isbn int,
PRIMARY KEY (id),
UNIQUE (isbn)
);To demonstrate how INNER JOINs work, we will join the users and addresses tables. In the previous chapter, we designed the user and address table to have a one-to-one relationship. In the data we set up, we have 3 users, but only 2 users have addresses. Alice Munro does not have an address.
Let's take a look at the data in the users table. Run the queries below in your PostgreSQL console and follow along to view results in the users and addresses tables.
SELECT * FROM users;
id | username | enabled | last_login
----+-------------+---------+----------------------------
1 | John Smith | t | 2016-04-03 11:53:18.730872
2 | Jane Smiley | t | 2016-04-03 11:53:18.74642
3 | Alice Munro | t | 2016-04-03 11:53:18.752364
(3 rows)SELECT * FROM addresses;
user_id | street | city | state
---------+-----------------+---------------+-------
1 | 1 Market Street | San Francisco | CA
2 | 2 Elm Street | San Francisco | CA
(2 rows)Now we will create an INNER JOIN between these two tables. An INNER JOIN returns a result set that contains the common elements of the tables, i.e the intersection where they match on the joined column. INNER JOINs are the most frequently used JOINs. In the query below, the line INNER JOIN (addresses) ON (users.id = addresses.user_id) creates the intersection between the two tables. Only 2 records are returned for the query; the result does not contain the user Alice Munro who does not have an address.
SELECT users.*, addresses.*
FROM users
INNER JOIN addresses
ON users.id = addresses.user_id;
id | username | enabled | last_login | user_id | street | city | state
----+-------------+---------+----------------------------+---------+-----------------+---------------+-------
1 | John Smith | t | 2016-04-03 11:53:18.730872 | 1 | 1 Market Street | San Francisco | CA
2 | Jane Smiley | t | 2016-04-03 11:53:18.74642 | 2 | 2 Elm Street | San Francisco | CA
(2 rows)INNER JOINs can be described by the Venn diagram's intersectionality which states that only the things that are in both of the sets are returned.

A LEFT JOIN or a LEFT OUTER JOIN takes all the rows from one table, defined as the LEFT table, and JOINs it with a second table. The JOIN is based on the conditions supplied in the parentheses. A LEFT JOIN will always include the rows from the LEFT table, even if there are no matching rows in the table it is JOINed with.
SELECT users.*, addresses.*
FROM users
LEFT JOIN addresses
ON (users.id = addresses.user_id);
id | username | enabled | last_login | user_id | street | city | state
----+-------------+---------+----------------------------+---------+-----------------+---------------+-------
1 | John Smith | t | 2016-04-03 11:53:18.730872 | 1 | 1 Market Street | San Francisco | CA
2 | Jane Smiley | t | 2016-04-03 11:53:18.74642 | 2 | 2 Elm Street | San Francisco | CA
3 | Alice Munro | t | 2016-04-03 11:53:18.752364 | | | |
(3 rows)What's being said in SQL is "give me all the matching rows from the left table along with any matching data from the RIGHT table based on the ON clause". In the above query, Alice Munro does not have an address. However, the query returns 3 records, and the address fields return NULL values for Alice Munro. In the INNER JOIN, Alice Munro's record was not returned at all.
LEFT JOINs can be described by the Venn diagram below.

A CROSS JOIN, also known as a Cartesian JOIN, returns all rows from one table crossed with every row from the second table. This JOIN does not have an ON clause.
This SQL query has the similar syntax to other JOINs, but without the ON clause
SELECT *
FROM users
CROSS JOIN addresses;
id | username | enabled | last_login | user_id | street | city | state
----+-------------+---------+----------------------------+---------+-----------------+---------------+-------
1 | John Smith | t | 2016-04-03 11:53:18.730872 | 1 | 1 Market Street | San Francisco | CA
1 | John Smith | t | 2016-04-03 11:53:18.730872 | 2 | 2 Elm Street | San Francisco | CA
2 | Jane Smiley | t | 2016-04-03 11:53:18.74642 | 1 | 1 Market Street | San Francisco | CA
2 | Jane Smiley | t | 2016-04-03 11:53:18.74642 | 2 | 2 Elm Street | San Francisco | CA
3 | Alice Munro | t | 2016-04-03 11:53:18.752364 | 1 | 1 Market Street | San Francisco | CA
3 | Alice Munro | t | 2016-04-03 11:53:18.752364 | 2 | 2 Elm Street | San Francisco | CA
(6 rows)The query above returns the addresses and users tables, cross joined. The result set consists of every record in users mapped to every record in addresses. For 3 users and 2 addresses, we get a total of 3x2=6 records. In mathematical terms, this is the cross product of a set.
In an application, usually we will not use a CROSS JOIN. More often than not, it's more important to match rows together through a JOIN, and then use the information returned. Therefore, using something like a CROSS JOIN to query for the cross product of all rows will most likely not return a meaningful result. It's still important to know of CROSS JOINs, since they do have their uses here and there. CROSS JOINs can be described by the Venn diagram below.
A RIGHT JOIN is similar to a LEFT JOIN except that all the data on the second table is included. When we set up our data earlier in this chapter, we created 3 books, but not all books are checked out by a user. The book My Third SQL Book does not have any user associated with it. When we run the RIGHT JOIN below, all books are returned in the result. Notice that though all books have been included, the username is returned as NULL for the book that is not associated with any user.
SELECT users.username, books.title
FROM users
RIGHT JOIN users_books ON (users_books.user_id = users.id)
RIGHT JOIN books ON (books.id = users_books.book_id);
username | title
-------------+--------------------
John Smith | My First SQL Book
John Smith | My Second SQL Book
Jane Smiley | My Second SQL Book
| My Third SQL Book
(4 rows)Now, notice that for the same query, if a LEFT JOIN is used instead of a RIGHT JOIN, all users are returned, even those with no books associated with them, but NOT all books are returned.
SELECT users.username, books.title
FROM users
LEFT JOIN users_books ON (users_books.user_id = users.id)
LEFT JOIN books ON (books.id = users_books.book_id);
username | title
-------------+--------------------
John Smith | My First SQL Book
John Smith | My Second SQL Book
Jane Smiley | My Second SQL Book
Alice Munro |
(4 rows)RIGHT JOINs can be described by the Venn diagram below.

In the next chapters, we will study advanced queries, functions, and operators in SQL queries. These topics require a solid understanding of relationships, joins and keys so make sure to revisit this chapter to learn them thoroughly.
One of the index types you're already using in your tables is the PRIMARY KEY, which PostgreSQL uses to uniquely identify a row in a table. The terms KEY and INDEX in PostgreSQL are somewhat synonymous.
You can also create a UNIQUE index on a column. We saw this in an earlier chapter where we added a unique constraint to the book table on the isbn column. Now when you create a SELECT query to search a book by its isbn, it will not scan the entire table and check each row; with the use of a unique index, that data can be accessed immediately, which should make the query very fast.
CREATE TABLE books (
id SERIAL,
title VARCHAR(100) NOT NULL,
author VARCHAR(100) NOT NULL,
published_date TIMESTAMP NOT NULL,
isbn INT,
PRIMARY KEY (id),
UNIQUE (isbn)
);When should I use an index? Indexes are best used in cases where sequential reading is inadequate. For example: fields that aid in mapping relationships and fields that are frequently displayed with ORDERED BY are good candidates for indexing. Misuse of indexes can slow down your database inserts/updates as indexes need to be updated appropriately. They are best used in tables where reads are more common.
You can create indexes for a table based on a single column, multiple columns or even the prefix of a column.
- Single column
- Multi-column
- A partial index can be set to check the prefix of a field, this will make it so this column is indexed by the prefix of the value.
CREATE INDEX ON table_name (field_name, other_field_name)The DROP INDEX command can be used to delete the index that was created. PostgreSQL generates unique names for all indexes. If you want to know the name generated you can run:
\diAs you can see the index created is named as books_author_idx. If you have been following along, go ahead and run the query below to DROP the index.
DROP INDEX books_author_idx;SELECT tbl_cep_201911_n_cidade.cidade, SQRT(
POW(69.1 * (tbl_cep_201911_n_log.latitude - -23.63), 2) +
POW(69.1 * (-46.6322 - tbl_cep_201911_n_log.longitude) * COS(tbl_cep_201911_n_log.latitude / 57.3), 2)) AS distance
FROM tbl_cep_201911_n_log
INNER JOIN `tbl_cep_201911_n_cidade`
ON tbl_cep_201911_n_log.cidade_id = tbl_cep_201911_n_cidade.id_cidade
HAVING distance < 25
ORDER BY distance LIMIT 0, 5;SELECT
tbl_cep_201911_n_cidade.cidade,
(
6371 *
acos(cos(radians(-23.63)) *
cos(radians(tbl_cep_201911_n_log.latitude)) *
cos(radians(tbl_cep_201911_n_log.longitude) -
radians(-46.6322)) +
sin(radians(-23.63)) *
sin(radians(tbl_cep_201911_n_log.latitude)))
) AS distance
FROM `tbl_cep_201911_n_log`
INNER JOIN `tbl_cep_201911_n_cidade`
ON tbl_cep_201911_n_log.cidade_id = tbl_cep_201911_n_cidade.id_cidade
HAVING distance < 28
ORDER BY distance LIMIT 0, 5;delete from address where address.id not
in (select members_address.addressId from members_address)