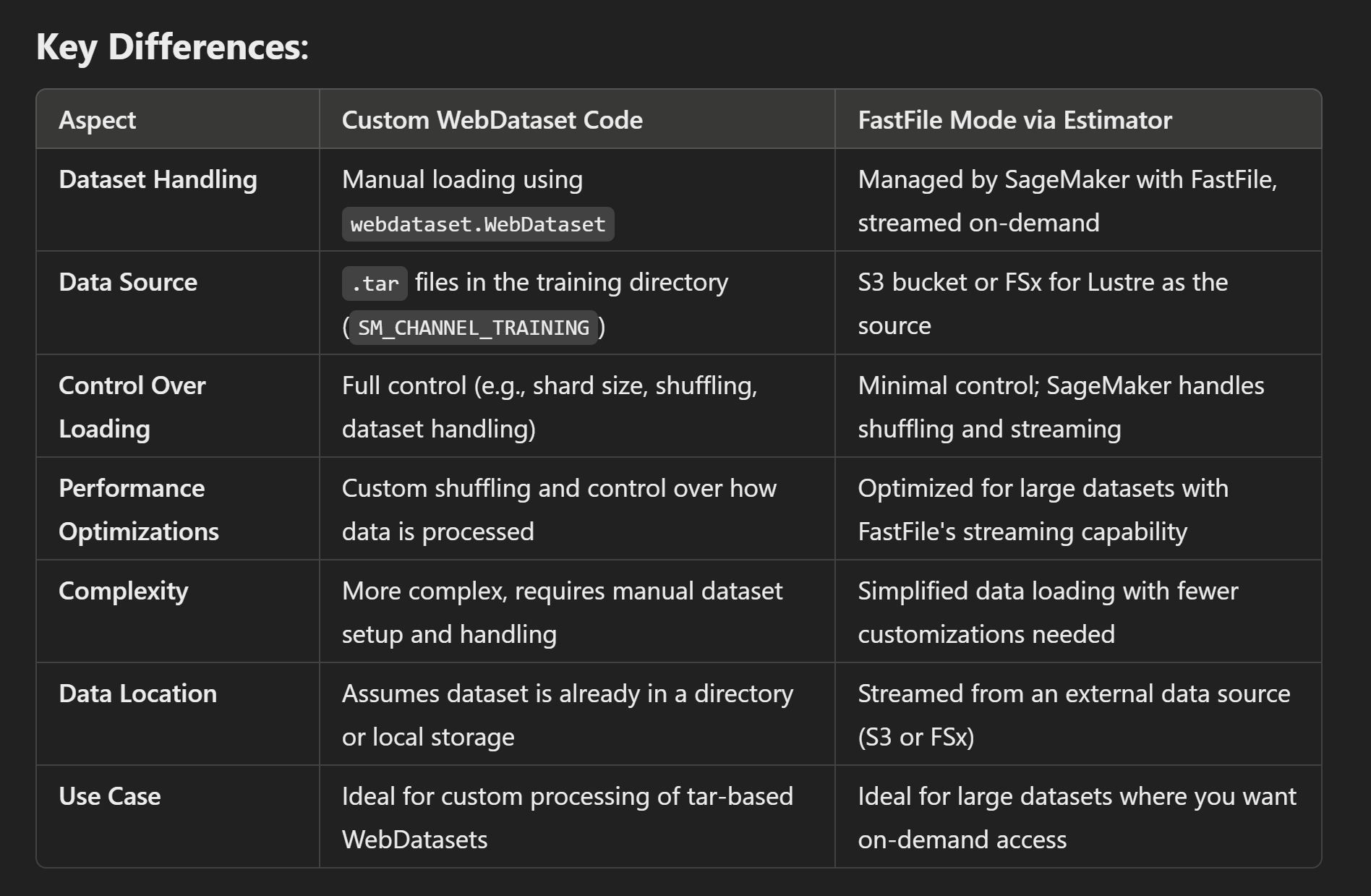
- WebDataset source code
https://github.com/webdataset/webdataset
Code snippets are from the following sources:
- ✅ Why I Chose WebDataset for Training on 50TB of Data?
Ahmad Sachal, May 22, 2023 - Training in PyTorch from Amazon S3: How to Maximize Data Throughput and Save Money
Chaim Rand, May 15, 2022 - Amazon SageMaker Fast File Mode
Methods for Streaming Training Data from Amazon S3 to Amazon SageMaker — Part 2
Chaim Rand, Nov 22, 2021
import torch, time
from statistics import mean, variance
dataset = get_dataset()
dl = torch.utils.data.DataLoader(dataset, batch_size=4, num_workers=4)
stats_lst = []
t0 = time.perf_counter()
for batch_idx, batch in enumerate(dl, start=1):
if batch_idx % 100 == 0:
t = time.perf_counter() - t0
print(f'Iteration {batch_idx} Time {t}')
stats_lst.append(t)
t0 = time.perf_counter()
mean_calc = mean(stats_lst[1:])
var_calc = variance(stats_lst[1:])
print(f'mean {mean_calc} variance {var_calc}')## measure how the step time changes when running on the streamed data samples
import torch, time
from statistics import mean, variance
dataset=get_dataset()
dl=torch.utils.data.DataLoader(dataset, batch_size=4, num_workers=4)
batch = next(iter(dl))
t0 = time.perf_counter()
for batch_idx in range(1,1000):
train_step(batch)
if batch_idx % 100 == 0:
t = time.perf_counter() - t0
print(f'Iteration {batch_idx} Time {t}')
t0 = time.perf_counter()- Create random synthetic data
import webdataset as wds
import numpy as np
from PIL import Image
import io
out_tar = 'wds.tar'
sink = wds.TarWriter(out_tar)
im_width = 1024
im_height = 1024
num_classes = 256
for i in range(100):
image = Image.fromarray(np.random.randint(0, high=256,
size=(im_height,im_width,3), dtype=np.uint8))
label = Image.fromarray(np.random.randint(0, high=num_classes,
size=(im_height,im_width), dtype=np.uint8))
image_bytes = io.BytesIO()
label_bytes = io.BytesIO()
image.save(image_bytes, format='PNG')
label.save(label_bytes, format='PNG')
sample = {"__key__": str(i),
f'image': image_bytes.getvalue(),
f'label': label_bytes.getvalue()}
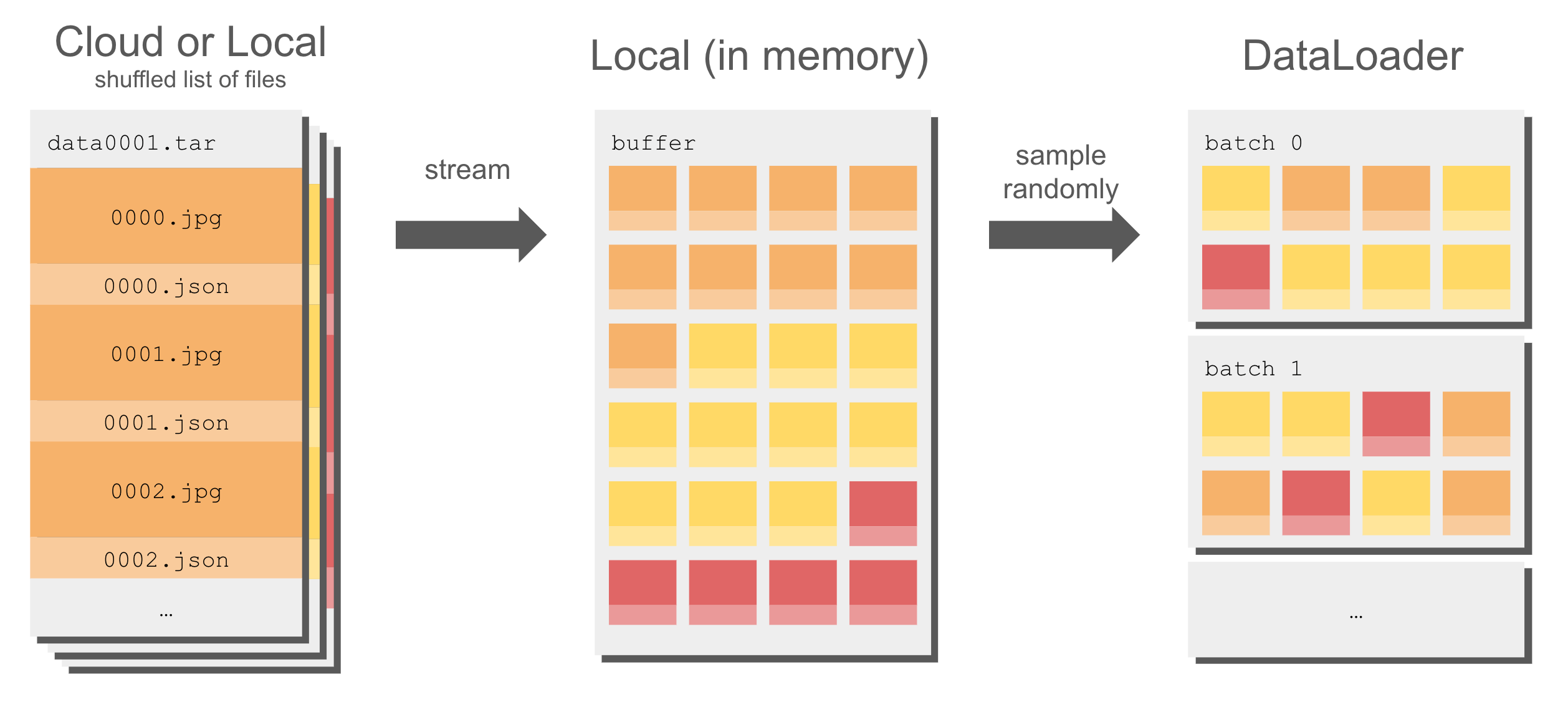
sink.write(sample)FastFileinput mode for SageMaker estimator
import os, webdataset
def get_dataset():
ffm = os.environ['SM_CHANNEL_TRAINING']
urls = [os.path.join(ffm, f'{i}.tar') for i in range(num_files)]
dataset = (
webdataset
.WebDataset(urls, shardshuffle=True) ## shard shuffle
.shuffle(10) ## buffer shuffle
)
return dataset