Mix.install([
{:kino, "~> 0.15.3"},
{:libgraph, "~> 0.16.0"}
])A graph is
A graph data structure consists of a finite (and possibly mutable) set of vertices (also called nodes or points), together with a set of unordered pairs of these vertices for an undirected graph or a set of ordered pairs for a directed graph. These pairs are known as edges (also called links or lines), and for a directed graph are also known as edges but also sometimes arrows or arcs.

A graph is circles and lines. Nodes and connections. Vertices and edges.

DAG stands for Directed Acyclic Graph
i.e. Circles with lines that have an arrow between them.
The "acyclic" means no "loop backs" i.e. there cannot be "cycles" where an arrow takes you back up the graph where you've already been.

DAGs are especially good at representing dataflow in a pipeline where each node/vertex represents a step where a computation occurs, transforming the input and producing a new output.
Once a step such as a in the image above completes, we know we can execute a and c in parallel.
All a dataflow graph is, is just data moving following the arrows down.
Dataflow Graphs naturally model parallelism.
Graphs can model programs which can change at runtime; managed dynamically.
Flink

Business workflow modeling
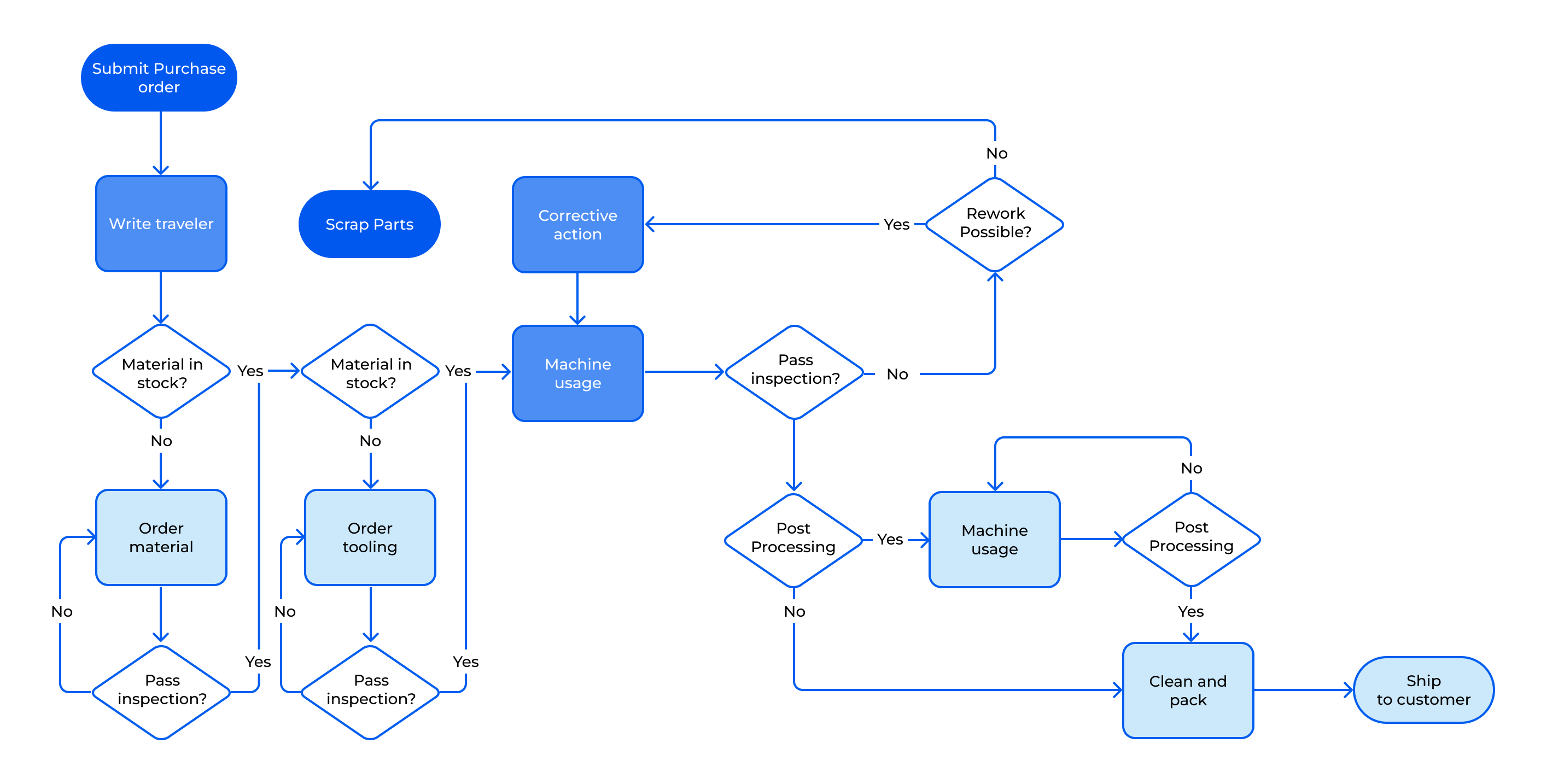
Streaming Materialized Views

Rete Network
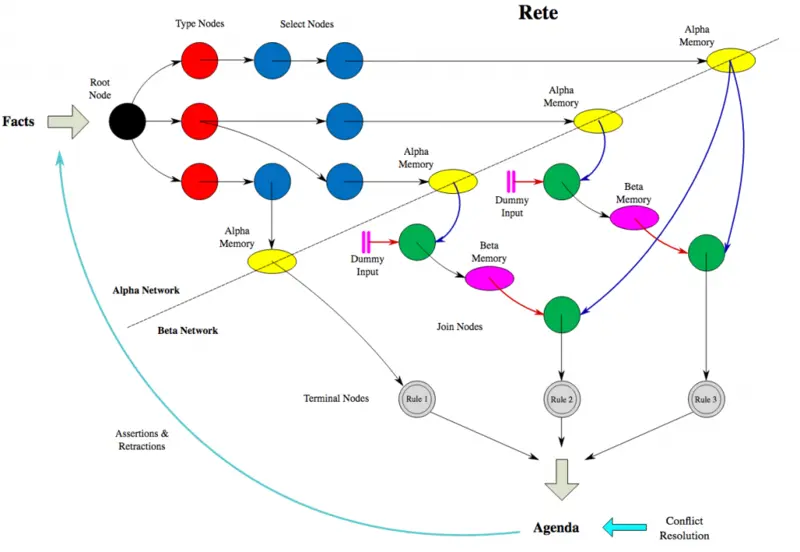
- ETL / Pipeline builder tools are DAGs
- Apache BEAM and most related high throughput data processing frameworks are graphs
- Flink is a leading data processing framework that implements the Apache BEAM standard.
- Apache Spark is also dataflow dags
- GCP Dataflow
- AWS Data Pipeline
- Differential Datalog
- Tensorflow is graphs
- No Code / Durable Execution / Serverless Models are DAGs
- AWS Lambda
- Google Cloud Functions
- Azure Functions
- Restate
- Rule & Workflow engines are DAGs
- RETE Algorithm
- Drools
- Redhat Decision Manager
- Camunda
- CPU scheduling is DAGs!
- Oban Pro Workflows
- Axon
- GraphQL / Absinthe
- Propcheck
- https://hex.pm/packages?search=depends%3Ahexpm%3Alibgraph
-
- Uses consistent hashing
:erlang.phash2/1and vanilla maps and mapsets
- Uses consistent hashing
-
- Implemented before Maps were in Erlang and uses ETS tables instead
defmodule GraphTools do
def to_mermaid(%Graph{} = graph) do
Enum.reduce(
Graph.edges(graph),
"graph TD;",
fn
%{v1: v1, v2: v2}, acc ->
acc <>
"#{vertex_id(v1)}([#{vertex_name(v1)}])-->#{vertex_id(v2)}([#{vertex_name(v2)}]);"
end
)
end
defp vertex_name(:root), do: :root
defp vertex_name(%{work: fun}), do: "step_#{fun_name(fun)}"
defp vertex_name(%{check: fun}), do: "cond_#{fun_name(fun)}"
defp vertex_name(fun) when is_function(fun), do: "fun_#{fun_name(fun)}"
defp vertex_name(vertex) when is_atom(vertex), do: to_string(vertex)
defp vertex_name(otherwise) do
try do
to_string(otherwise)
catch
_any -> :erlang.phash2(otherwise)
end
end
defp vertex_id(thing) when is_atom(thing), do: to_string(thing)
defp vertex_id(thing), do: :erlang.phash2(thing)
defp fun_name(fun), do: Function.info(fun, :name) |> elem(1)
endg =
Graph.new(type: :directed)
|> Graph.add_edges([
{:a, :b},
{:a, :c},
{:b, :d}
])
g
|> GraphTools.to_mermaid()
|> Kino.Mermaid.new()Functions are just data and graphs are data structures, so what if we put functions in our graphs?
fun_1 = fn num -> num * 2 end
fun_2 = fn num -> num + 2 end
fun_3 = fn num -> num * 42 end
fun_4 = fn num -> num + 42 end
fun_dag =
Graph.new(type: :directed)
|> Graph.add_edges([
{:root, fun_1},
{fun_1, fun_2},
{fun_1, fun_3},
{fun_2, fun_4}
])
fun_dag
|> GraphTools.to_mermaid()
|> Kino.Mermaid.new()For some input
- start at the top and run that function with the input to get a new output
- find the next step(s) by traveling down the arrows (i.e. the
out_neighbors) - feed the output from the previous step into the next steps
- Profit
input = 42
neighbors_of_root = Graph.out_neighbors(fun_dag, :root)first_runnables = Enum.map(neighbors_of_root, fn fun -> {fun, input} end)first_result =
first_runnables
|> Enum.map(fn {fun, input} -> fun.(input) end)
|> List.first()fun_from_first_runnable = first_runnables |> List.first() |> elem(0)
neighbors_of_first_runnable =
fun_dag
|> Graph.out_neighbors(fun_from_first_runnable)
|> Enum.map(fn fun -> {fun, first_result} end)
|> Enum.map(fn {fun, input} ->
fun.(input)
end)Wow neat - but why couldn't we just do this in normal code?
- Parallelization opportunities
- Change the dag at runtime
neighbors_of_first_runnable =
fun_dag
|> Graph.out_neighbors(fun_from_first_runnable)
|> Task.async_stream(fn fun ->
fun.(first_result)
end)
|> Enum.map(fn {:ok, result} -> result end)used Flow, Genstage, Pools of Genservers, spawn primitives, poolboy, oban, rabbitmq, ..........
new_fun_dag = Graph.add_edge(fun_dag, fun_from_first_runnable, fn _num -> 42 end)
new_fun_dag
|> GraphTools.to_mermaid()
|> Kino.Mermaid.new()-
Graphs are everywhere because they're useful for modeling relationships between things such as task dependencies (e.g. dataflow)
-
Elixir is well suited for building things with dataflow graphs because the runtime is built for concurrency and distribution
Graphs let us model parallelism in a runtime-modifiable program enabling a "functional-core imperative shell" separation of concerns